What is an Open Table Format? & Why to use one?
- 1. Introduction
- 2. What is an Open Table Format (OTF)
- 3. Why use an Open Table Format (OTF)
- 4. Conclusion
- 5. Further reading
- 6. References
1. Introduction
If you are in the data space, you might have heard of open table formats such as Apache Iceberg, Apache Hudi, or Delta Lake. If you are wondering:
What is an open table format? & How is it different from file formats like Parquet or ORC?
What are the pros and cons of using an open table format? & How does it work?
Is it just a pointer to some metadata files and helps you sift through the data quickly?
Then this post is for you. Understanding the underlying principles behind open table formats will enable you to deeply understand what happens behind the scenes and make the right decisions when designing your data systems.
This post will review what open table formats are, their main benefits, and some examples with Apache Iceberg. By the end of this post, you will know what OTFs are, why you use them, and how they work.
2. What is an Open Table Format (OTF)
TL;DR Open table formats are wrappers around your data store & uses a series of files to
- Track schema/partition (DDL) changes on your table.
- Track the table’s data files & their column statistics.
- Track all the Inserts/Updates/Deletes (DML) on your table.
Storing a chronological series of files with all the DDL and DML statements applied to your table & index of the data file locations enables
- Schema & Partition Evolution
- Travelling back in time to a previous table state
- Creating table branches & tagging table state (similar to git)
- Handling multiple reads & writes concurrently
Here is an architecture comparison of Apache Iceberg, Apache Hudi & Delta Lake (ref ).
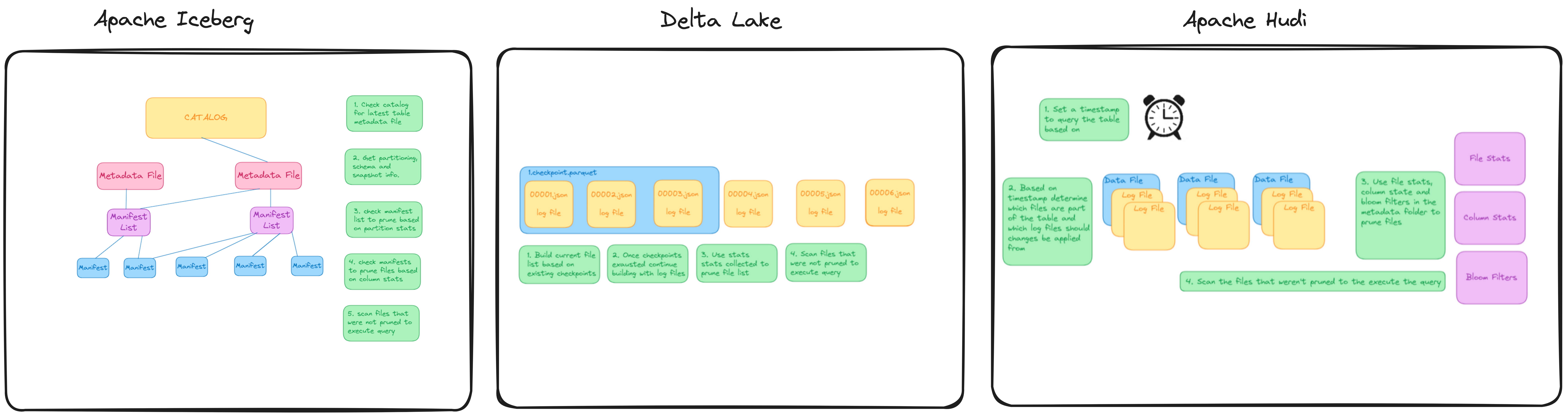
Note: When we refer to metadata in the following sections, we refer to the files that store information about DMLs, DDL, and column statistics. Every OTF has its naming conventions.
3. Why use an Open Table Format (OTF)
We will use Apache Iceberg to illustrate the benefits of using an OTF. While there are differences in implementation and minor differences, the below sections also apply to Apache Hudi and Delta format.
3.0. Setup
Following along with the code is recommended! Please follow the setup section in this GitHub repo to create and insert data into the orders table.
Apache Iceberg can work with multiple data processing systems; we use spark-sql in our examples.
3.1. Evolve data and partition schema without reprocessing
Apache Iceberg enables you to change your table’s data schema or partition schema without reprocessing the existing data. The metadata files track schema & partition changes, allowing the systems to process data using the appropriate data/partition schema for the corresponding historical data.
Schema and partition evolution are common operations in analytical tables and are often expensive or error-prone with traditional OLAP systems. Apache Iceberg makes data and partition schema evolution a simple task.
For example:
-- schema evolution
ALTER TABLE local.warehouse.orders ALTER COLUMN cust_id TYPE bigint;
ALTER TABLE local.warehouse.orders DROP COLUMN order_status;
-- parititon evolution
ALTER TABLE local.warehouse.orders ADD PARTITION FIELD cust_id;
INSERT INTO local.warehouse.orders VALUES
('e481f51cbdc54678b7cc49136f2d6af7',69,CAST('2023-11-14 09:56:33' AS TIMESTAMP)),
('e481f51cbdc54678b7cc49136f2d6af7',87,CAST('2023-11-14 10:56:33' AS TIMESTAMP));
-- check snapshots
select committed_at, snapshot_id, manifest_list from local.warehouse.orders.snapshots order by committed_at desc;
-- We will have two since we had two insert statements
-- See the partitions column statistics and data files added per snapshot
select added_snapshot_id, added_data_files_count, partition_summaries from local.warehouse.orders.manifests;
The above code shows that each operation on the table (set of Inserts/Deletes/Updates) will be considered a snapshot. We can also see the partition schema, column statistics, & number of files added or deleted per snapshot via the table’s manifests.
We can also open the file ./data/iceberg-warehouse/warehouse/orders/metadata/v<the latest number>.metadata.json (in your project directory) to see the different data and partition schemas under the “schemas” and “partition-specs” sections, respectively.
A visual representation of how systems work with data whose partitions have evolved:
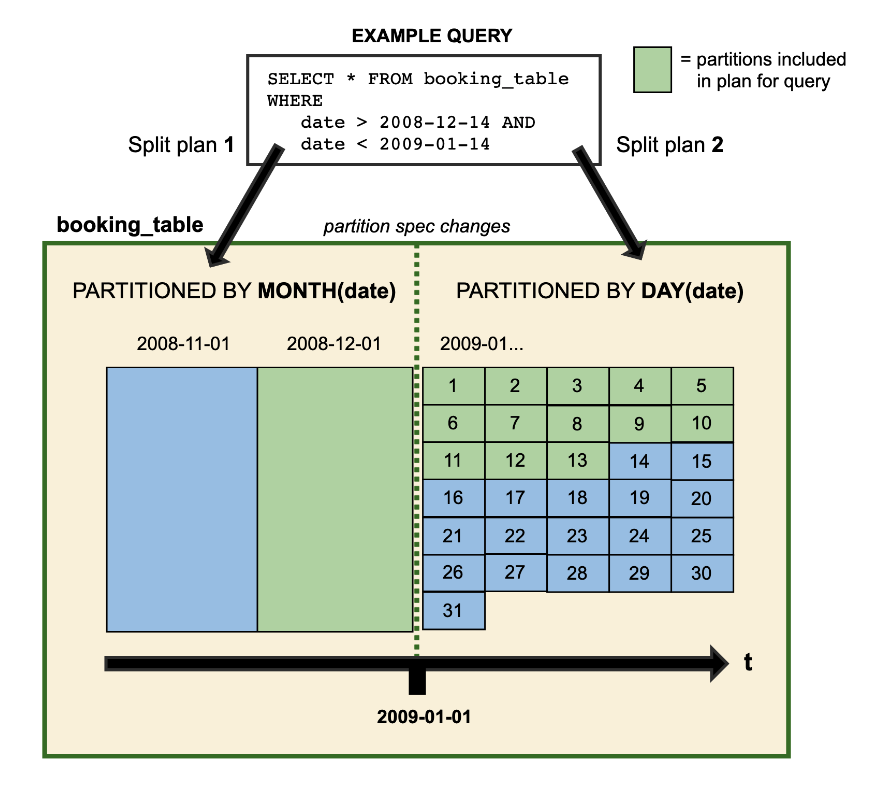
Hidden partition lets you define(& enable use of) partitions based on column transformations. E.g., you may want to partition by date on a timestamp column. In HIVE (without OTFs), you must create a separate date column in the data. However, with Apache Iceberg, you can define a partition on a transformation of another column, as shown below:
/* -- created in the setup section
CREATE TABLE local.warehouse.orders (
order_id string,
cust_id INT,
order_status string,
order_date timestamp
) USING iceberg
PARTITIONED BY (date(order_date));
*/
-- The below query automatically uses the partition to prune data files to scan.
SELECT cust_id, order_date FROM local.warehouse.orders WHERE order_date BETWEEN '2023-11-01 12:45:33' AND '2023-11-03 12:45:33';
3.2. See previous point-in-time table state, aka time travel
Since metadata files track all the changes in data (& data/partition schema), we can return to a point-in-time table state(aka time travel). E.g., If you want to see what a table looked like four days ago, you can do this using time travel.
-- get the time of the first data snapshot
select min(committed_at) as min_committed_at from local.warehouse.orders.snapshots;
-- e.g. 2023-11-21 12:03:08.833
-- Query data as of the oldest committed_at (min_committed_at from the above query) time or after
SELECT * FROM local.warehouse.orders TIMESTAMP AS OF '2023-11-21 12:03:08.833';
-- 15 rows
-- Query without time travel, and you will see all the rows
SELECT * FROM local.warehouse.orders;
-- 17 rows
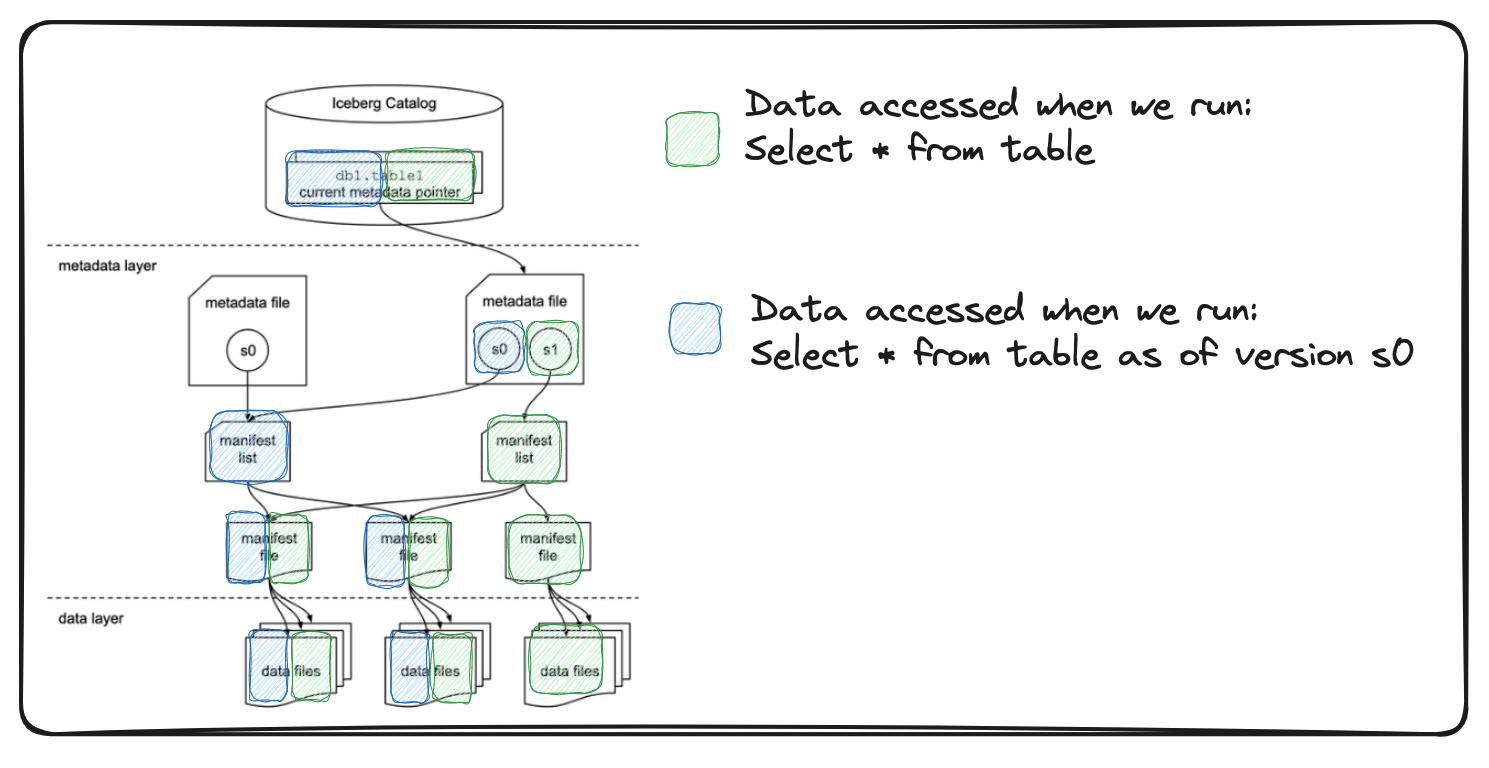
Note: For Apache Iceberg, as your data size grows, it’s recommended to clean up old snapshots .
3.3. Git like branches & tags for your tables
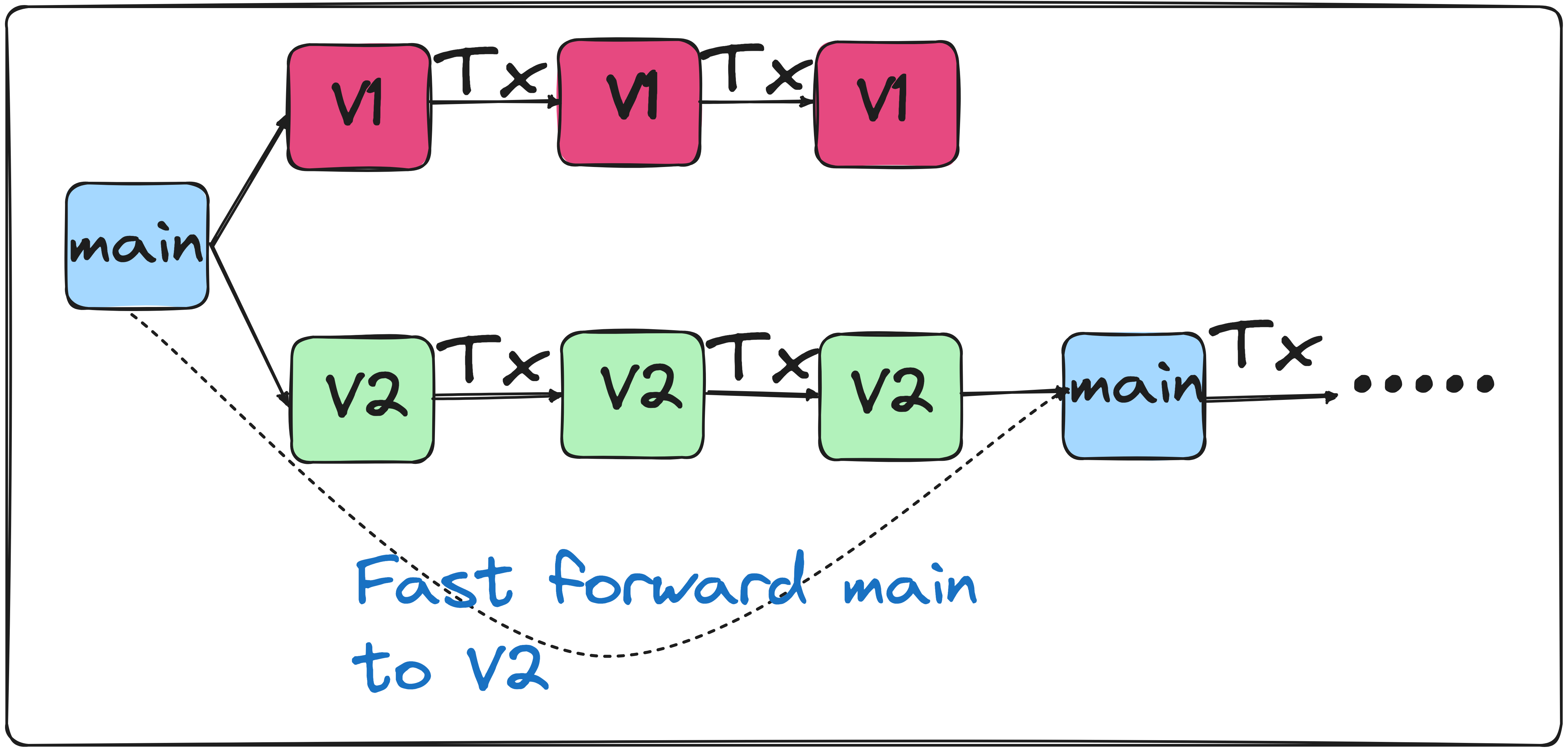
Apache Iceberg enables the branching of tables by managing isolated metadata files per branch. For example, assume you have to run a pipeline in production for a week to validate that the changes you made are valid. You can do this using branches as shown below:
DROP TABLE IF EXISTS local.warehouse.orders_agg;
CREATE TABLE local.warehouse.orders_agg(
order_date date,
num_orders int
) USING iceberg;
INSERT INTO local.warehouse.orders_agg
SELECT date(order_date) as order_date, count(order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-02' GROUP BY 1;
-- Create two branches that are both stored for ten days
ALTER TABLE local.warehouse.orders_agg CREATE BRANCH `branch-v1` RETAIN 10 DAYS;
ALTER TABLE local.warehouse.orders_agg CREATE BRANCH `branch-v2` RETAIN 10 DAYS;
-- Use different logic for each of the branches
-- inserting into branch v1
INSERT INTO local.warehouse.orders_agg.`branch_branch-v1`
SELECT date(order_date) as order_date, count(order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-03' GROUP BY 1;
INSERT INTO local.warehouse.orders_agg.`branch_branch-v1`
SELECT date(order_date) as order_date, count(order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-04' GROUP BY 1;
-- inserting into branch v2
INSERT INTO local.warehouse.orders_agg.`branch_branch-v2`
SELECT date(order_date) as order_date, count(distinct order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-03' GROUP BY 1;
INSERT INTO local.warehouse.orders_agg.`branch_branch-v2`
SELECT date(order_date) as order_date, count(distinct order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-04' GROUP BY 1;
-- validate data, the v2 logic is correct
select * from local.warehouse.orders_agg.`branch_branch-v1` order by order_date;
select * from local.warehouse.orders_agg.`branch_branch-v2` order by order_date;
From the above exercise, we notice that branch-v2 has the correct logic, so we fast forward the main branch to branch-v2. The main branch will now have the accurate data for the past two days.
select * from local.warehouse.orders_agg order by order_date desc;
-- Push the main branch to branch v2's state
CALL local.system.fast_forward('warehouse.orders_agg', 'main', 'branch-v2');
select * from local.warehouse.orders_agg order by order_date desc;
3.4. Handle multiple reads & writes concurrently
In traditional OLAP systems (e.g., HIVE), if multiple processes read/write to the same table without proper safeguards, there may be inconsistent data reads, or data may get overwritten during writes. Apache Iceberg atomically updates its metadata, which forces writers to “commit” their changes one at a time (if multiple writers collide, there will be a retry for the failed writer ).
When reading data, Apache Iceberg uses the most recent snapshot (using a metadata file) to ensure that no in-process data operations impact reads.
Since Apache Icerber is OSS, we can use any system that implements the table format to be able to read and write.
E.g., We can use DuckDB to read our data. Exit your spark shell with exit; and docker with exit. Start DuckDB CLI with the duckdb command via your terminal.
INSTALL iceberg;
LOAD iceberg;
-- Count orders by date
WITH orders as (SELECT * FROM iceberg_scan('data/iceberg-warehouse/warehouse/orders', ALLOW_MOVED_PATHS=true))
select strftime(order_date, '%Y-%m-%d') as order_date
, count(distinct order_id) as num_orders
from orders
group by strftime(order_date, '%Y-%m-%d')
order by 1 desc;
4. Conclusion
To recap, Open table formats are wrappers around your data store & use a series of files to
- Track schema/partition (DDL) changes on your table.
- Track the table’s data files & their column statistics.
- Track all the Inserts/Updates/Deletes (DML) on your table.
Storing a chronological series of files with all the DDL and DML statements applied to your table & index of the data file locations enables
- Schema & Partition Evolution
- Travelling back in time to a previous table state
- Creating table branches & tagging table state (similar to git)
- Handling multiple reads & writes concurrently
The next time you work with OTFs, remember that it’s a system of metadata files, storing every change to the data, & statistical information about data files. OTFs can significantly improve how you manage analytical tables and developer experience.
If you have any questions or comments, please leave them in the comment section below.
5. Further reading
- Comparing Apache Hudi, Apache Iceberg, Delta Lake
- Z-Ordering
- Parquet
- Partitioning
- Git branch & tag
- Apache Iceberg Inspecting tables
- Partition Transformation functions
- Schema on read v schema on write
6. References
If you found this article helpful, share it with a friend or colleague using one of the socials below!