Enable stakeholder data access with Text-to-SQL RAGs
- 1. Introduction
- 2. TL;DR
- 3. Enabling Stakeholder data access with RAGs
- 3.1. Set up
- 3.2. Loading: Read raw data and convert them into LlamaIndex data structures
- 3.3. Indexing: Generate & store numerical representation of your data
- 3.4. Querying: Ask LLM your question with the relevant context
- 3.4.1. Retriever: Use user query and get relevant contextual data
- 3.4.2. Node Post Processor: Optionally transform relevant contextual data for your use case
- 3.4.3. Response Synthesizer: Use user query, relevant context, and prompts to ask LLM question(s)
- 3.4.4. Routing: Chose a strategy to use to ask LLM the user query
- 4. Conclusion
- 5. Next steps
- 6. Further reading
- 7. References
1. Introduction
Have you tried to improve your organization’s skills by trying to teach stakeholders SQL? Learning SQL is a win-win for the stakeholders and the data team. Because the stakeholders gain valuable SQL expertise and free up the data engineers. But more often than not:
Stakeholders do not put in the effort to learn SQL
Stakeholders still ping DEs for ad-hoc data requests (even a simple SQL query)
Your time spent trying to teach SQL to stakeholders will have been wasted!
Most people will choose the easiest way to do their jobs, even if it is extremely inefficient.
When stakeholders want data, it may be quicker for them to ask a data engineer than to figure out how to write an SQL statement to get the necessary data. While you can’t force stakeholders to learn SQL to access data, a middle-ground approach can help them learn by repetition.
This is where LLMs come in. In this post, we will build an RAG pipeline that can create queries for the stakeholders to run. Over time, as stakeholders use this tool, they will become familiar with the SQL syntax and be able to write SQL queries themselves.
By the end of this post, you will know how to build a RAG (Retrieval Augmented Generation) pipeline. You will use your data to generate SQL for your stakeholder’s questions.
2. TL;DR
We will go over the critical stages of a RAG pipeline. The stages are
Loading: This stage involves reading raw data (.sql, .md, .pptx, etc.) files and transforming them into LlamaIndex’s internal structure of documents and nodes.Indexing & Storing: This stage involves creating and storing a numerical (or other options) representation of the document and nodes. The stored numerical data will be used when querying to provide the LLM API with the context most relevant to the user’s query.Querying: This stage represents taking a user query and using the stored index to get relevant context. The user query and the appropriate context are sent to the LLM API to get the results.Evaluation: This stage involves using objective metrics to measure the quality of the responses.

3. Enabling Stakeholder data access with RAGs
RAG pipelines are a way to ask LLMs (Open AI, etc.) questions while giving them the relevant information needed to answer them.
Our objective is to enable stakeholders to ask an analytical question and obtain an SQL query. The stakeholder is supposed to run the SQL query manually and, over time, improve with SQL.
3.1. Set up
We will build our RAG pipeline using LlamaIndex .
GitHub Repo: Data Helper
3.1.1. Pre-requisite
3.1.2. Demo
We will clone the repo setup poetry shell as shown below:
git clone https://github.com/josephmachado/data_helper.git
cd data_helper
poetry install
poetry shell # activate the virtual env
# To run the code, please set your OPEN AI API key as shown below
export OPENAI_API_KEY=your-key-here
python run_code.py INDEX # Create an index with data from ./data folder
python run_code.py QUERY "Show me for each buyer what date they made their first purchase."
# The above command uses the already existing index to request LLM API to get results
# The code will return a SQL query with DuckDB format
python run_code.py QUERY "For every seller, show me a monthly report of the number of unique products that they sold, avg cost per product, and the max/min value of the product purchased that month."
# The code will return a SQL query with DuckDB format
3.1.3. Key terminology
User query: The question asked by the user.LLM, Large Language Model: LLMs are designed to generate text responding to a question. The generated text is based on vast data used to train the LLM.RAG, Retrieval Augmented Generation: A technique to retrieve information relevant to the user query from provided documents and send this relevant information & user query to LLM to generate a helpful response.
3.2. Loading: Read raw data and convert them into LlamaIndex data structures
Loading refers to reading data from data sources and converting it into data structures that store information about the data and their relationships.
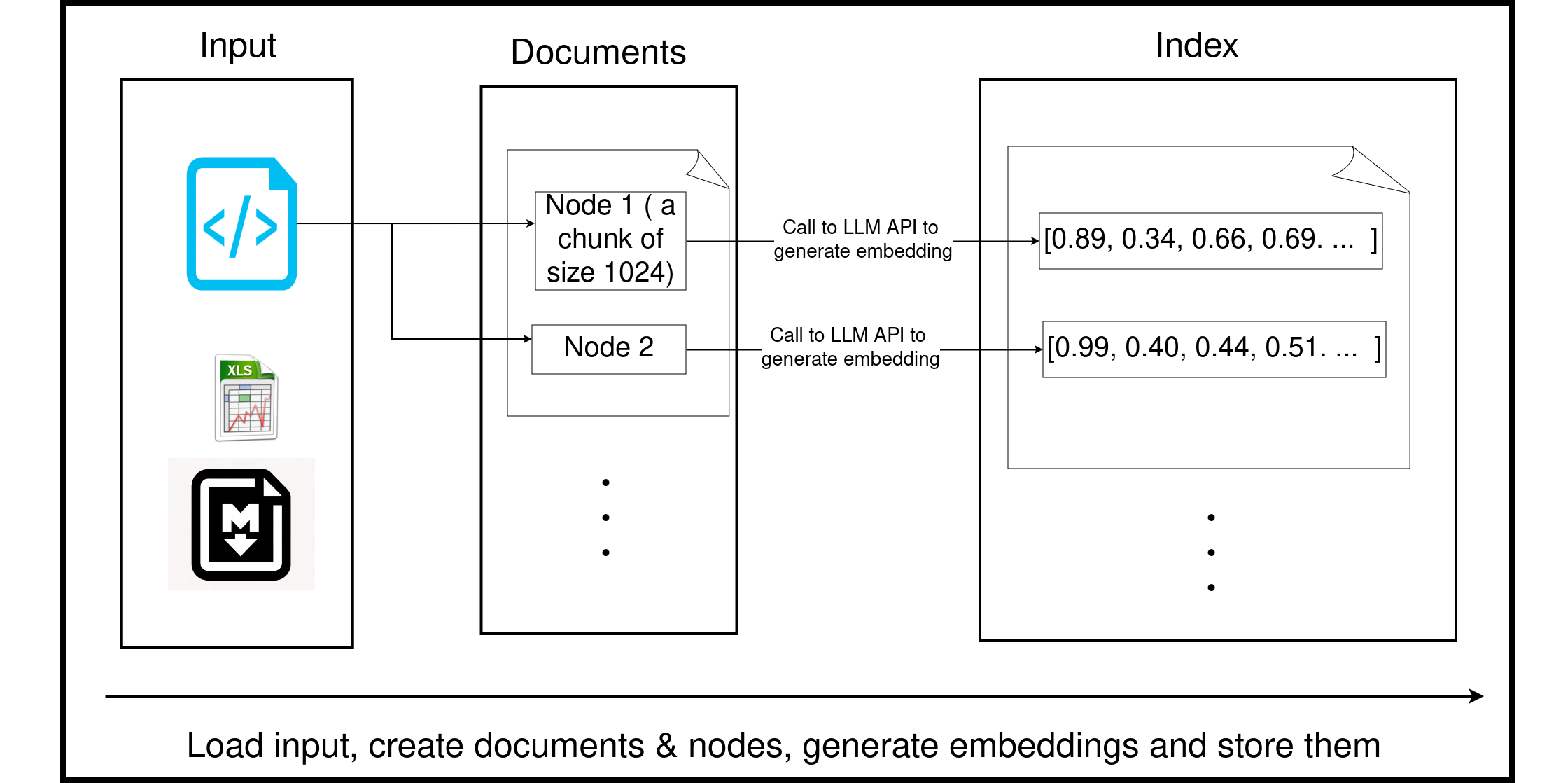
3.2.1. Read data from structured and unstructured sources
We need to provide relevant information that can be used to answer user queries. The relevant information can be both structured and unstructured data. In the read step, our pipeline reads the appropriate data from multiple sources (Tables, SQL query, DDL, markdown, Excel, etc.).
LlamaIndex provides tools for loading data from multiple sources: LlamaHub Readers .
To achieve our objective of responding with a working SQL query in response to a stakeholder question, we should use data that can help provide LLM the context to generate SQL queries. An easy way to do this is to use a DDL script that has the definition of all our schemas and tables as the RAG input.
We use a DDL script (with ample comments, aliases, and metrics definitions) to tell the LLM the right tables and column names to use to generate a working query.
The additional documentation provides context and aliases commonly used by stakeholders to ensure a good response. We can add more input sources, such as documentation about business flow, conceptual data models, etc. The more specific and concise the input, the better the output generated.
Let’s look at part of our input (the entire file is at ./data/data_schema.sql ), note the comments:
-- Table 'dim_buyer' (alias: Buyer, Customer, Client) stores detailed buyer information. Grain: individual buyer, Unique key: buyer_id
DROP TABLE IF EXISTS dim_buyer;
CREATE TABLE dim_buyer (
buyer_id INT, -- Unique identifier for the buyer (alias: BuyerID, CustomerID, ClientID)
user_id INT, -- Identifier linking to the user account (alias: UserID, AccountID)
username VARCHAR(255), -- Username of the buyer (alias: UserName, Nickname)
email VARCHAR(255), -- Email address of the buyer (alias: EmailAddress, ContactEmail)
is_active BOOLEAN, -- Status to check if the buyer's account is active (alias: ActiveStatus, IsActive)
first_time_purchased_timestamp TIMESTAMP, -- Timestamp of the buyer's first purchase (alias: FirstPurchase, FirstBuyDate)
created_ts TIMESTAMP, -- Timestamp when the buyer record was created (alias: CreationTime, RecordCreated)
last_updated_by INT, -- Last user/admin who updated the buyer record (alias: UpdatedBy, ModifiedBy)
last_updated_ts TIMESTAMP -- Timestamp when the buyer record was last updated (alias: UpdateTime, LastModified)
);
Code to read data from our ./data folder (full code at index_manager.py
):
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader(data_folder).load_data()
3.2.2. Transform data into LlamaIndex data structures
LlamaIndex has a data structure designed to split large input data into smaller chunks while retaining information about the data itself(metadata) and how the smaller chunks are related.
LlamaIndex’s internal way of storing input data is called documents and nodes. Let’s go over a quick description of them:
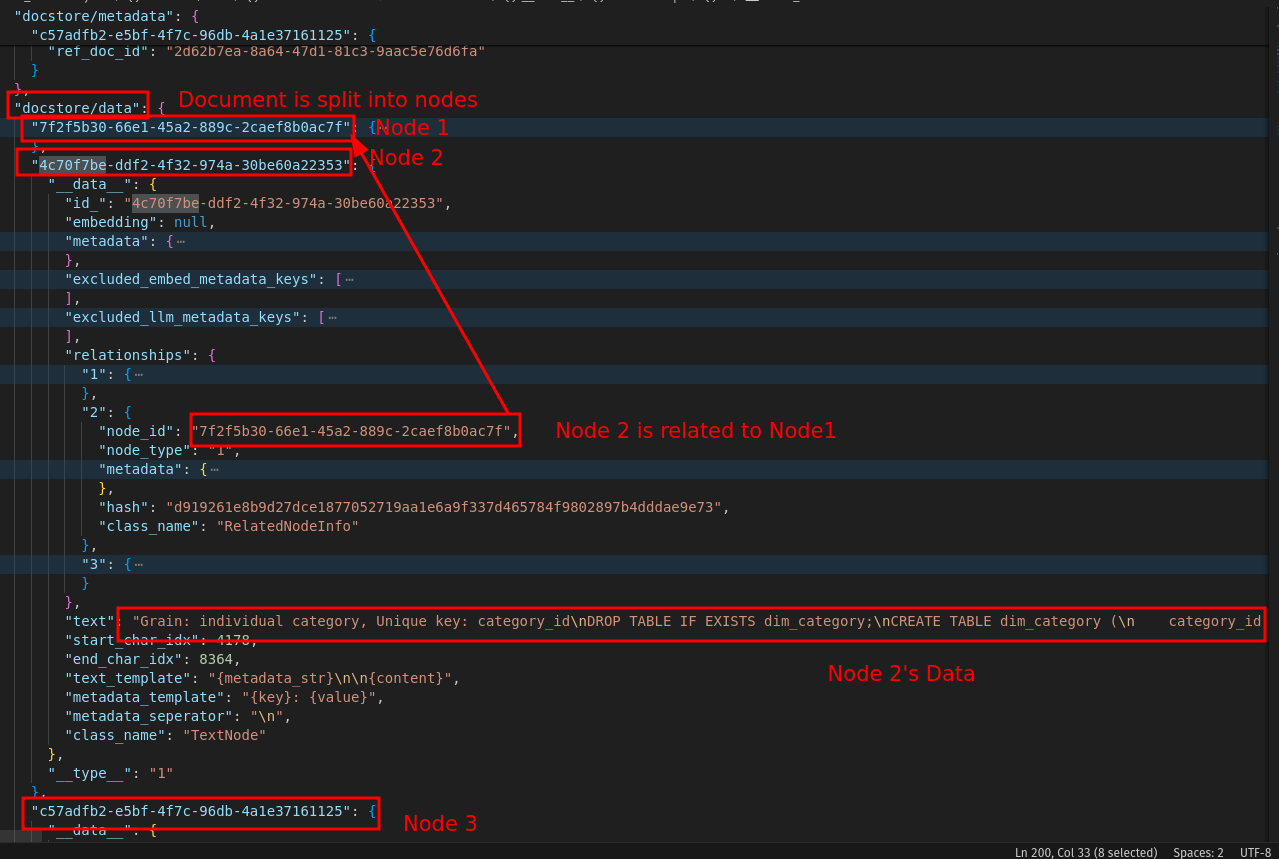
Document: This corresponds to a document (.docx, .md, .sql, .xlsx, etc.) read in by the reader. We can add metadata to the documents, which will be useful when we query the data. The metadata can act as a keyword-based search to find relevant context during querying.Node: Each document comprises multiple nodes. By default, a document is chunked into 1024 bytes, with each chunk corresponding to a node. In addition, every node will overlap 20 bytes with its adjacent chunks.
This also includes metadata about where the raw document is, how nodes are related to documents, and how nodes relate to each other.
Let’s see how our document (and its nodes) are stored (this is a formatted version seen here: formatted_docstore )
3.3. Indexing: Generate & store numerical representation of your data
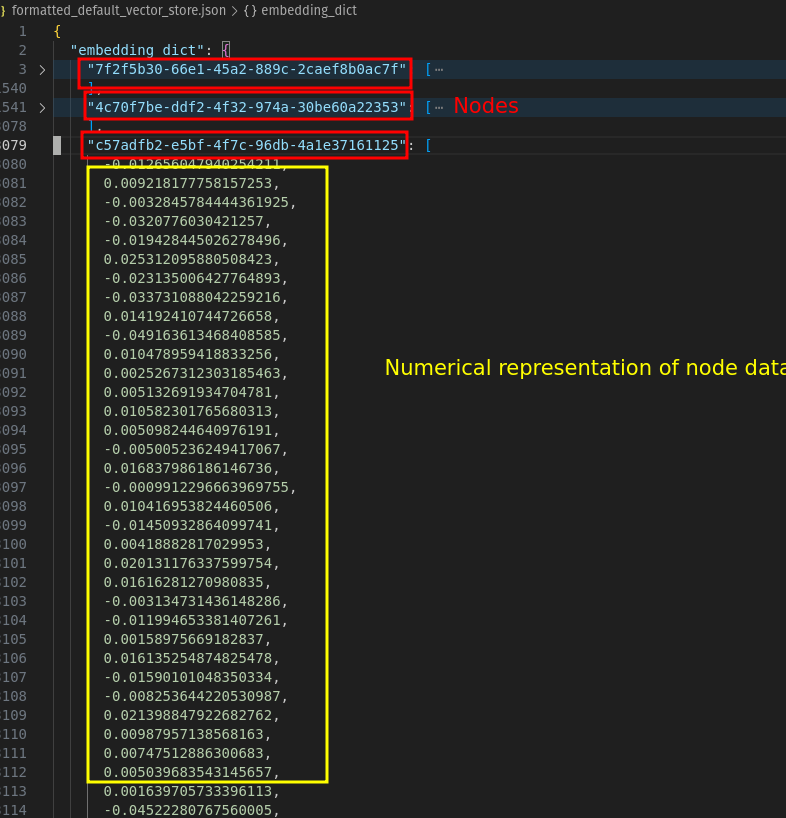
During the querying phase, the RAG will use an index created from input data to find the information most relevant to the user’s query. Indexing is the process of creating these indexes.
While there are different types of indexes (some of which don’t require embedding), we will use vector indexing, which is by far the most popular indexing.
In most text-based models, data is represented by a vector (array of numbers) called embeddings. To get relevant information in the querying phase, we need to ensure that the same model is used to generate embeddings for both the indexing and retrieval phase (which is where RAG gets the relevant information for a given user query).
Using the same process to generate embedding in both phases ensures we can use similarity metrics to find the relevant context.
Our nodes are converted to embeddings using the LLM API (OpenAI API in our case). The results are stored in a database (local file in our case ).
Code to generate & store index from our raw data (complete code at index_manager.py ):
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist()
3.4. Querying: Ask LLM your question with the relevant context
Querying refers to the process of responding to a user query .
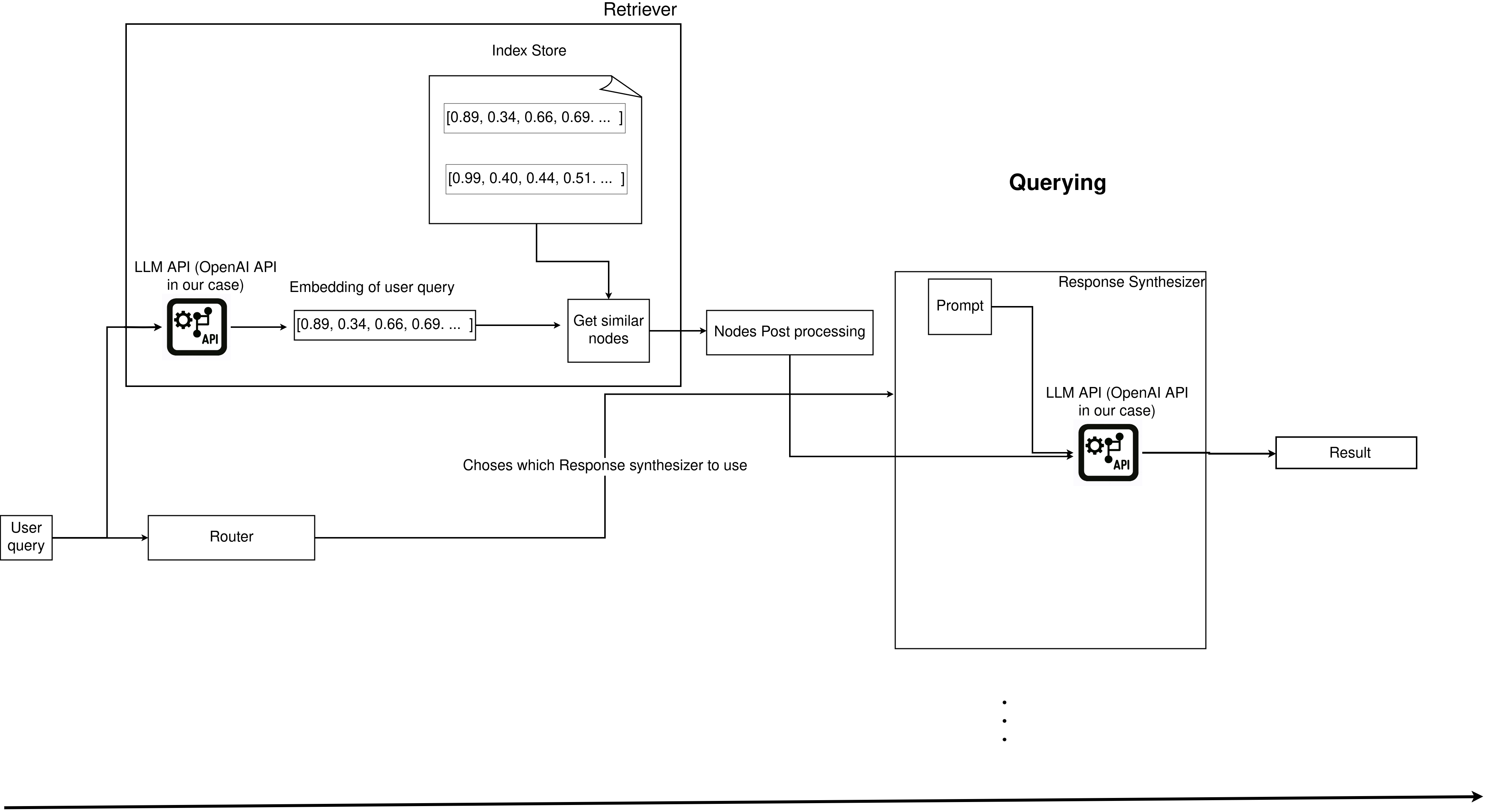
We will go over the individual components of querying, but LlamaIndex provides a way to query LLM with relevant context simply as shown below (full code at query_manager.py ):
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
index = load_index_from_storage(storage_context)
query_str = "Your stakeholder question"
query_engine = index.as_query_engine()
print(query_engine.query(query_str))
3.4.1. Retriever: Use user query and get relevant contextual data
The retriever is responsible for getting the nodes that are most relevant to a user query. The process of retrieval depends on the index store. Since we are using a vector index, the user query will be converted into an embedding (using OpenAI’s API) and used to calculate the K nearest nodes in the index.
By default, cosine similarity is used to identify the k similar nodes.
Depending on the types of index, there are other ways to retrieve “relevant” nodes .
Code to retrieve relevant node (full code at query_manager.py ):
retriever = index.as_retriever()
retrieved_nodes = retriever.retrieve(query_str)
3.4.2. Node Post Processor: Optionally transform relevant contextual data for your use case
The retriever gives you a list of “relevant” nodes. You can optionally decide to transform these nodes. You can use the time of node creation as a metric to rank recent data higher, use LLMs to re-rank the nodes, have a higher threshold of what it means to be a relevant node, or define your own processor.
The node post-processing step allows you to fine-tune the relevant information being sent to the LLMs. Multiple processor functions are available here .
In our code, we use a SimilarityPostProcessor to keep only nodes with a similarity threshold of 0.7 or higher.
Code to process retrieved node (full code at query_manager.py ):
from llama_index.core.postprocessor import SimilarityPostprocessor
"""
We can use one of the postprocessors here (or write our own)
https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/node_postprocessors/#node-postprocessor-modules
"""
# We use a simple similarity post processor to define a similarity threshold
processor = SimilarityPostprocessor(similarity_cutoff=0.70)
filtered_nodes = processor.postprocess_nodes(retreived_nodes)
3.4.3. Response Synthesizer: Use user query, relevant context, and prompts to ask LLM question(s)
A response synthesizer is responsible for taking the user query, adding the text from the relevant (and transformed)nodes and prompts and asking the question to the LLM and sending the response back to the user.
With a response synthesizer, we can control how questions are asked to the LLM APIs. LlamaIndex has multiple response modes to choose from: here .
refine: Create and refine an answer by sequentially going through each retrieved text chunk. This makes a separate LLM call per Node/retrieved chunk, which is good for more detailed answers.compact(default) is similar to refine but compacts (concatenates) the chunks beforehand, resulting in fewer LLM calls. In short, it is like refine, but with fewer LLM calls.tree_summarize: Query the LLM using the summary_template prompt as many times as needed so that all concatenated chunks have been queried, resulting in as many answers that are themselves recursively used as chunks in a tree_summarize LLM call and so on, until there’s only one chunk left, and thus only one final answer. Suitable for summarization purposes.simple_summarize: Truncate all text chunks into a single LLM prompt. It is suitable for quick summarization purposes but may lose detail due to truncation.no_text: Only runs the retriever to fetch the nodes that would have been sent to the LLM without actually sending them. Then, it can be inspected by checking the response.source_nodes.accumulate: Given a set of text chunks and the query, apply the query to each text chunk while accumulating the responses into an array. Returns a concatenated string of all responses. It is suitable for when you need to run the same query separately against each text chunk.compact_accumulate: The same as accumulate, but will “compact” each LLM prompt similar to compact and run the same query against each text chunk.
Code to ask LLM our question with a response synthesizer(full code at query_manager.py ):
from llama_index.core import get_response_synthesizer
from llama_index.core.response_synthesizers import ResponseMode
response_mode = ResponseMode.COMPACT_ACCUMULATE
response_synthesizer = get_response_synthesizer(response_mode=response_mode)
response = response_synthesizer.synthesize(query_str, filtered_nodes)
3.4.4. Routing: Chose a strategy to use to ask LLM the user query
When building complex RAGs, such as one that can respond with an SQL query, explain the business, explain the product market fit, etc., you need to ensure that the appropriate response synthesizer is being used.
Routing is an optional feature that allows you to define which response synthesizer to use to respond to a user query. We define a selector mechanism to decide which response synthesizer to use.
The core router modules exist in the following forms(ref docs ):
- LLM selectors put the choices as a text dump into a prompt and use the LLM text completion endpoint to make decisions
- Pydantic selectors pass choices as Pydantic schemas into a function calling endpoint and return Pydantic objects
Note that routers can be used to select among any of the modules above, such as which data to use, which index to use, etc.
4. Conclusion
We reviewed the following to achieve our objective of enabling stakeholders to ask analytical questions and empowering them to run SQL.
- Getting data relevant to the questions that stakeholders can ask
- Converting the data from the above step into indexed
- Using indexes to get relevant information for a user query and asking LLMs the question intelligently with context
While RAGs are an excellent efficiency booster, they come with their tradeoffs:
- Not consistently accurate
- May write inefficient queries, causing costs to skyrocket
- False sense of correctness, especially by people not proficient with the data or SQL
- DEs being held responsible for decisions made by data from incorrectly generated SQL query
Suppose the correct expectations are set, and RAGs are used in a controlled manner. In that case, they can significantly improve efficiency (SQL skills for stakeholders, reduced DEs ad hoc query time, teaching people about the data present in the warehouse).
If you have successfully used RAGs in production or have any questions about how to do this, don’t hesitate to contact me at help@startdataengineering.com or leave a comment below.
5. Next steps
- Evaluate results and tune the pipeline
- Add an observation system
- Monitor API costs
- Add additional documentation as input
- Explore other use cases such as RAGs for onboarding, DE training tool, etc
6. Further reading
7. References
If you found this article helpful, share it with a friend or colleague using one of the socials below!
Thank you for this insightful article on data democratization and the role of LLMs. Your explanation of how large language models can empower more people to access and utilize data is both inspiring and informative. It’s exciting to see how these advancements can bridge gaps and foster innovation. I’m curious about the challenges you foresee in ensuring data quality and privacy as more users gain access to these tools. Do you have any recommendations for best practices in maintaining these standards while promoting wide accessibility? Looking forward to your thoughts and more great content!