Data Engineering Interview Preparation Series #2: System Design
- 1. Introduction
- 2. Guide the interviewer through the process
- 2.1. [Requirements gathering] Make sure you clearly understand the requirements & business use case
- 2.2. [Understand source data] Know what you have to work with
- 2.3. [Model your data] Define data models for historical analytics
- 2.4. [Pipeline design] Design data pipelines to populate your data models
- 2.5. [Data quality] Ensure you quality check your data before usage
- 2.6. [Data storage] Store your data based on query patterns
- 2.7. [Backfill] Define how the pipeline will be re-run(aka backfill) without issues when things go wrong
- 2.8. [Discoverability] How would end users identify the data they want to use
- 2.9. [Observability] Define a way for end users to be able to observe how “ready” a dataset is
- 2.10. [Data-ops] How will changes to your data pipeline be deployed to production
- 3. Be ready to dive into popular technologies
- 4. Conclusion
- 5. Essential reading
1. Introduction
System design interviews are usually vague and depend on you (as the interviewee) to guide the interviewer. If you are thinking:
How do I prepare for data engineering system design interviews?
I am struggling to think of questions you would ask in a system design interview for data engineering
I don’t have enough interview experience to know what companies ask
Is data engineeing “system design” more than choosing between technologies like Spark and Airflow?
This post is for you! Imagine being able to solve any data systems design interviews systematically. You’ll be able to showcase your abilities and demonstrate clear thinking to your interviewer.
By the end of this post, you will have a list of questions ordered by concepts that you can use to approach any data systems design interview.
This post is part 2 of my data engineering interview series:
- Data Engineering Interview Preparation Series #1: Data Structures and Algorithms
- Data Engineering Interview Preparation Series #2: System Design
- Data Engineering Interview Preparation Series #3: SQL
2. Guide the interviewer through the process
In systems design interviews, you are expected to guide your interviewer through a structured set of steps to the objective. We will go over the steps in the following sections, but you need to know how to talk about them.
When conversing with the interviewer:
- Lead the conversation. Ask for requirements, narrate your thought process, and state any assumptions you are making.
- Be open to feedback. The interviewer will try to guide you in the direction they want you to concentrate. Listen carefully to the interviewer’s words and focus on their discussion.
- Be honest, do not lie. Never lie about a tool or technique you are not 100% clear about; you will dig yourself into a hole you can’t escape. Most interviewers can detect lies.
The objective is to show the interviewer that you have user empathy (requirements gathering, enabling end users), building pipelines, and ensuring maintainability.
In the following sections, we will review the concepts you will discuss during your interviews. Each section has two parts: the first part shows the concepts/questions to discuss, and the second part shows the outcome from each part before proceeding.
Note that depending on your interview, the order may change.
2.1. [Requirements gathering] Make sure you clearly understand the requirements & business use case
Before starting to design, you need to understand your user. Here is a list of questions you can ask to ensure you know your end user.
- Who is the end user(s)? What team(s) are they a part of?
- What data are they looking for?
- why do they need this data? What is the business use case?
- Is this request part of a broader initiative or a one-off request? This question shows that you are considering the big picture.
- How fast does the data need to be made available? Does the end user need data in under 5 min or 1 hour?
- What critical metrics does the end user care about in this data? How are these metrics defined?
- How will the end user access the data: prebuilt dashboards, SQL, or APIs?
The requirements are usually pretty well scoped; if not, make assumptions (e.g., If the interviewer doesn’t specify latency, assume batched hourly and state it out loud)
Outcomes:
- Key metrics
- End-user access patterns
- What business entities do we need to report?
- Data latency SLAs
2.2. [Understand source data] Know what you have to work with
Get a good understanding of the data you have access to. Knowing your data and how to access it is crucial for designing your pipelines.
Here is a list of questions to get answers for (or make and state your assumptions to):
- What is the business process that generates this input data? (e.g., customer checkouts, etc.)
- Where is the input data stored?
- How can you access input data, such as SQL, Kafka, APIs, SFTP, S3, etc.?
- How often does the upstream business process change? If frequent, will you be informed prior to any upstream data schema changes?
- Dig into input data access questions:
- Do you have access to historical data from input, or do you have to store data for any later backfills ?
- What is the input data: is it a change log, API logs, data from SQL at points in time, etc?
- Does the input source have data duplication?
- If your source is API, is it rate limited? What would the size of the input data be?
- Does input schema change without data teams getting notified?
- What is the exact input data format? Is it tabular, json, protobuf, etc?
Outcomes:
- business process that generates the data
- input source systems (client, databases, SFTP, cloud storage, APIs, )
- Input data set specifics: data schema, data source inconsistencies,
- Need to handle changing schema
2.3. [Model your data] Define data models for historical analytics
With knowledge of your data and the data that end users want, you can begin to design your pipeline. Before jumping into the tech, you should clearly define the tables that your pipeline will produce.
Here is a list of steps that you can follow to define your data model:
- Use the 3-hop architecture. Most companies use dbt and/or Spark for their pipelines—both dbt flow and medallion (databricks recommended architecture) for the 3-hop pattern.
- Start by defining your silver tables: The facts and dimension tables .
- Define the join keys for the silver tables.
- If the dimensional data can change over time, use SCD2 .
- In order to keep the metric definition in your code base, use OBT and aggregated tables .
- Specify the different layers:
- raw: raw data from upstream sources, as is dumped into a cloud store/raw table.
- bronze: raw -> data types and naming conventions applied
- silver: bronze -> transformed to facts and dimensions
- gold: facts and dimensions -> OBT (optionally) -> aggregate tables with metrics for direct use by end users or BI layer
- If the fact table is large (usually the case), use a partition to store the data in separate folders. The columns to partition by typically are the time/day when the data event occurred and also by the most commonly filtered column. Mention that you are considering partitioning in this stage; you can expand on this later in the data storage section .
Outcomes:
- Data flow architecture: raw -> bronze -> silver -> gold.
- Defined facts, dimensions, OBT, and aggregate tables with their data schemas.
- Data partitions for large fact and OBT tables.
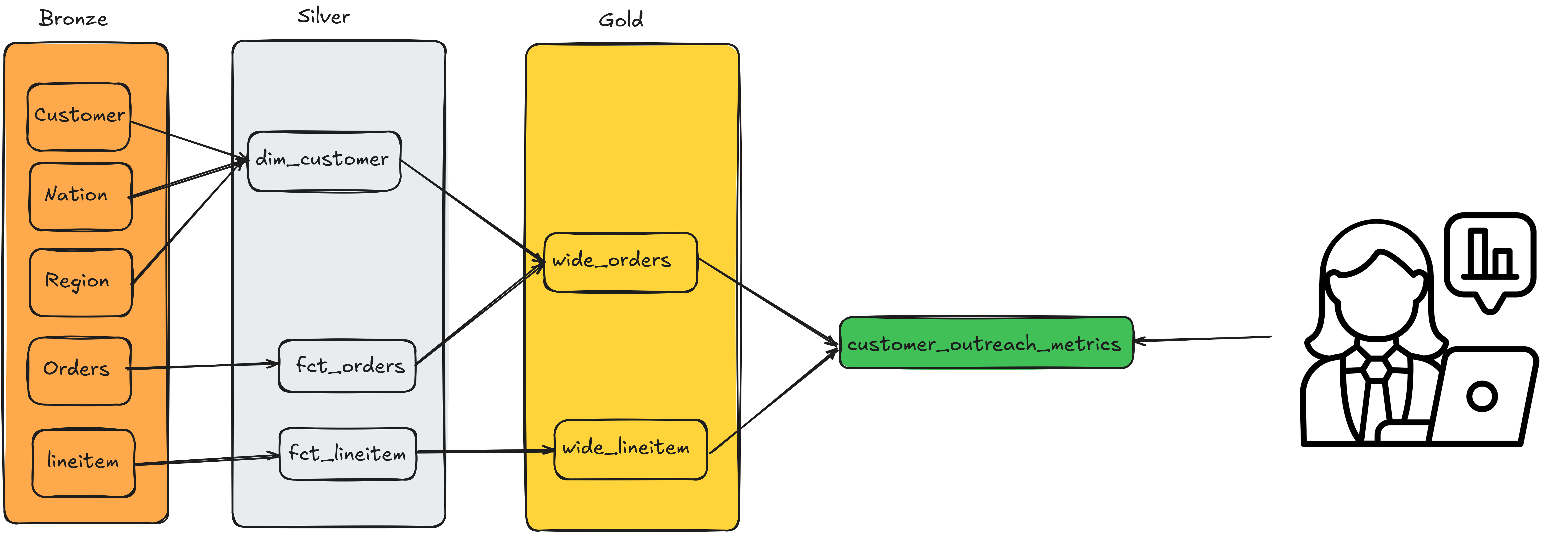
2.4. [Pipeline design] Design data pipelines to populate your data models
At this stage, you have the inputs and destination tables well defined. Your next steps are to define how you will extract, transform, and load the data.
Here is a list of steps to talk through to define data processing steps:
- Data extract: Pull data from input sources.
- If API source: Check if you can pull data in parallel or have to pull it serially.
- If SQL source: Check if you can pull data from a clone so as not to put pressure on the production db.
- If log queue source: Check if you can pull the data in parallel; if the order of data matters at this stage, the possibility of duplicates.
- Specify that you can design the extract step to be a separate pipeline; if our data processing pipeline fails, it will not impact the extraction pipeline. Separation of extraction from processing can help deal with data loss in a non-replayable input source .
- Data processing tool: Typically a large data processing tool like Spark or Snowflake (sql v python ). Talk about the size of the data and existing data infrastructure. If the data size is small (< 50 GB), opt to specify that a single node in the memory processing system (e.g., DuckDB, Polars) can be a simpler/cheaper solution at this time.
- Write code/logic to transform input data into facts/dimensions (silver) and further into OBT and aggregates. Dig into
MERGE INTOfor SCD2 dimensions. Specify data deduplication if applicable. - If the interviewer asks about making data available quickly while also ensuring the accuracy of older data, you will want to discuss lambda and kappa architecture .
Outcomes:
- Logic is used to extract data from the source.
- Code/logic transforms data from the source to silver and then to gold tables.
- Show expertise with advanced architecture such as Lambda/Kappa.
2.5. [Data quality] Ensure you quality check your data before usage
With the tables defined, you must ensure they are correct before exposing them to end users. Here are a list of things to talk with the interviewer about data quality:
- Discuss how your data should be “correct” before exposing it to the end user since making decisions based on incorrect data is usually not possible(or very difficult) to change.
- Explain the write-audit-publish pattern
- Explain the types of DQ checks: constraint checks, business checks, & metric variance (outlier detection) over time.
- Explain the order of priority of adding tests: Start with testing the output first
- Explain how storing results of DQ check runs can help analyze failure patterns and use that information to make pipeline resilient
Outcomes:
- Show that you care about how your data is used by implementing DQ checks
- What DQ checks to run
- Where the DQ checks need to be
2.6. [Data storage] Store your data based on query patterns
A key aspect of data usability and cost management is storing data appropriately. Shown below are a list of common data storage ideas to talk about:
- You need to store your data for efficient access based on data access patterns and common query filters.
- For commonly filtered columns, use the following storage patterns
- partition for low cardinality columns
- bucketing for high cardinality columns
- sorting for filtered columns based on ranges (e.g., age between x and y). Talk about Z-order for multi-column sorting
- Specify that you can mix the above approaches, such as partitioning by event day and sorting the data inside by timestamp. Also note that each platform/tool can have its own limitations (e.g., the number of partitions per table).
- Talk about how, ideally every file(that makes up a table) should be of a specific size 128MB to 256MB for effective parallelism data processing by most tools (Spark, Snowflake), and too many small files will result in wasted time in the form of data reading
- Dig into how parquet makes disk reads efficient based on a query, reading footer & column chunk seeks .
- Dig into how table formats (e.g., Iceberg) have metadata that can help to revert bad writes (e.g., time travel )
Outcomes:
- Show that you are paying attention to cost and user experience by using appropriate data storage techniques.
- Define exactly how the fact/OBT data is stored: partitions, bucketing, sorting
2.7. [Backfill] Define how the pipeline will be re-run(aka backfill) without issues when things go wrong
Bugs are inevitable; you will end up having to re-run your pipelines. Here are some things to talk about when it comes to re-runs (aka backfills ):
- Explain how your pipeline can be re-run without causing data duplication.
- Ensure that your pipeline processes a specified input data set and does not run based on time.now().
- Talk about idempotency and its tradeoffs with backfilling
Outcomes:
- How will your system do backfills without causing duplicates?

2.8. [Discoverability] How would end users identify the data they want to use
If you are interviewing at a large organization, talk about how you can use information about the data (e.g., tags, metadata, lineage, documentation) to allow end users to identify datasets that they’d want to use.
You could specify tools that allow you to do this: Amundsen , DataHub , etc
Outcomes:
- Show that you are thinking about the end-user experience
2.9. [Observability] Define a way for end users to be able to observe how “ready” a dataset is
Ensure that your end user has a good way to know if a dataset is ready for consumption. Data observability is a wide topic, but you can specify these points as a starting place:
- Describe a dashboard that shows how “ready” a dataset is.
- This dashboard should show the SLA of a dataset and how the current state of that dataset is
- This dashboard should also show if the dataset is meeting all of its defined data quality checks
- The information should be made available in a readiness table/API for use by downstream consumers to check before they start consuming
Outcomes:
- Demonstrate how you empower end users to be able to check the status of a dataset before using it.
2.10. [Data-ops] How will changes to your data pipeline be deployed to production
If you have time, talk about how you’d design your development workflow and how you can use CI/CD to ensure that your code changes produce the right data before being pushed into production.
Outcomes:
- Demonstrate your thinking about deploying code to production without causing issues.
3. Be ready to dive into popular technologies
While it’s uncommon for interviewers to dig into specifics, it can happen sometimes. Understand the following concepts to be ready to answer them:
- Separation of compute, storage, and metadata layer in popular data processing engines
- Orchestrating data pipeline: you don’t need to dig into Airflow specifics (unless specifically asked for), but knowing which parts of a data pipeline can be parallelized vs not will be helpful
- Reducing data shuffle
- Handling streaming concerns: data duplication, late arriving data, faulty data, watermarking .
4. Conclusion
To recap, we saw:
- How to lead the interview, while changing course based on feedback.
- Nailing down requirements
- Designing and building pipelines
- Maintaining pipelines
- Data usability
The next time you prepare for a systems design interview, use the steps above to help guide you.
Please let me know in the comment section below if you have any questions or comments.
5. Essential reading
- Advanced SQL
- Python for data engineers
- Data flow & code patterns
- Data quality checks
- Data streaming
- User requirement gathering
- Data warehouse
- Backfilling
- Data-ops: CI/CD
If you found this article helpful, share it with a friend or colleague using one of the socials below!
Great article! Thanks for the writeup.
Thank you :)
Great article!
Great content Joseph! All the nitty gritty details of DE.
Your site is f***ing superb. I'm a solo data engineer who was recently promoted to senior after only my first year. Your site has helped me feel comfortable with the fundamentals and get exposure to larger company best practices that I can bring to the table at my mid-sized company.
Thank you for the very kind words! Glad that my site has been helpful. Would be great to know how/which best practices you have implemented at your company!
Hi joseph, Your articles are really great source to build DE concepts and apply in your day to day worklife. From current article (part 2.9. [Observability] Define a way for end users to be able to observe how “ready” a dataset is) how can we implement this is Grfana. Any insight you can provide on this will be great help.
Thank you :) There are a couple ways to define ready. Some define it as the latest time a data was loaded(freshness), or the amount of data that was loaded, etc. I have parts of it defined here https://www.startdataengineering.com/post/de_best_practices_log/#31-metadata-information-about-pipeline-runs--data-flowing-through-your-pipeline but a comprehensive list is something that I am working on.
As for visualizing it in Grafana, checkout this repo: https://github.com/josephmachado/data_engineering_best_practices_log/tree/main?tab=readme-ov-file#setup