How to Manage Upstream Schema Changes in Data Driven Fast Moving Company
- 1. Introduction
- 2.Strategies for data teams to handle changing schemas
- 3. Conclusion
- 4. Recommended reading
1. Introduction
If you have worked at a company that moves fast (or claims to), you’ve inevitably had to deal with your pipelines breaking because the upstream team decided to change the data schema!
If you are
Frequently in meetings, fixing pipeline issues due to schema changes
Stressed, unable to deliver quality work, always in a hurry to put out the next fire
Working with teams who have to prioritize speed over everything
This post is for you. Constantly dealing with broken pipelines due to upstream data changes is detrimental to your career and leads to burnout.
What if you could focus on building great data projects? Imagine pipelines auto-correcting themselves! This post will enable you to do that.
We will discuss the strategies for handling upstream schema changes. These strategies will help you move from constant fire-fighting mode to a stable way of dealing with breaking upstream changes.
Upstream data schema changes are caused by:
- Column level change: New column, column deletions, data type changes.
- Table level change: Grain change, table name change, table swap, primary key change, join key change, etc
- Business process change: Introducing new tables/removing tables, new relationships, etc
2.Strategies for data teams to handle changing schemas
We will review four strategies for changing schemas and mix-and-match them for your use case.
2.1. Meetings are the most straightforward approach
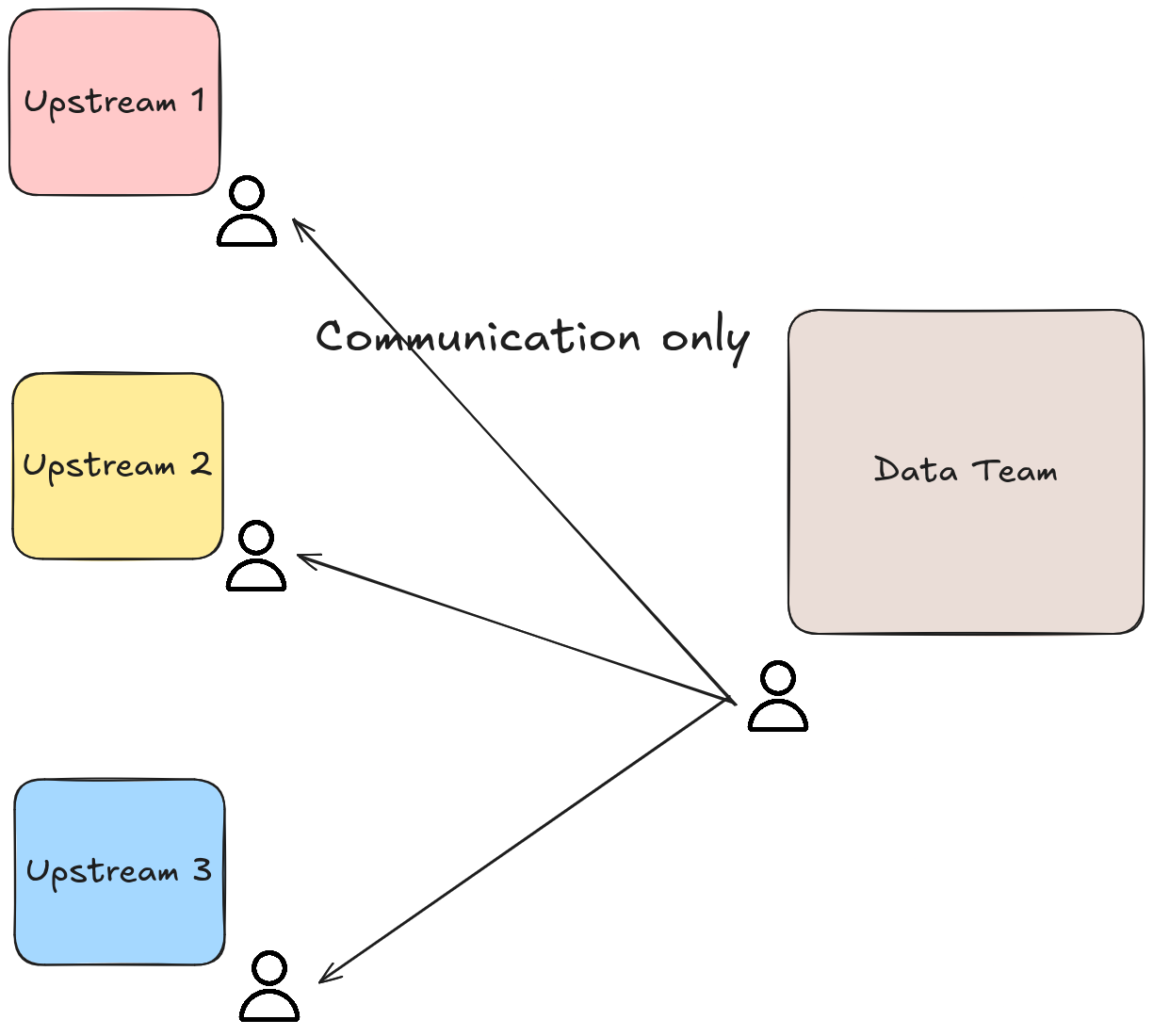
Upstream and data teams proactively communicate with each other before a big change and agree on timelines and schemas before any change is made to upstream datasets.
✅ Pros:
- Simplest approach
- Documentation in docs/confluence, etc
- Handshake between teams on a schema
❌ Cons:
- Error prone
- Meetings slow down development speed
- Not every nuance in data can be captured
🎯 How-to:
- Notes with clean to-dos
- Notes and decisions logged in Confluence or Google Docs
2.2. Upstream dumps data, data team deals with it
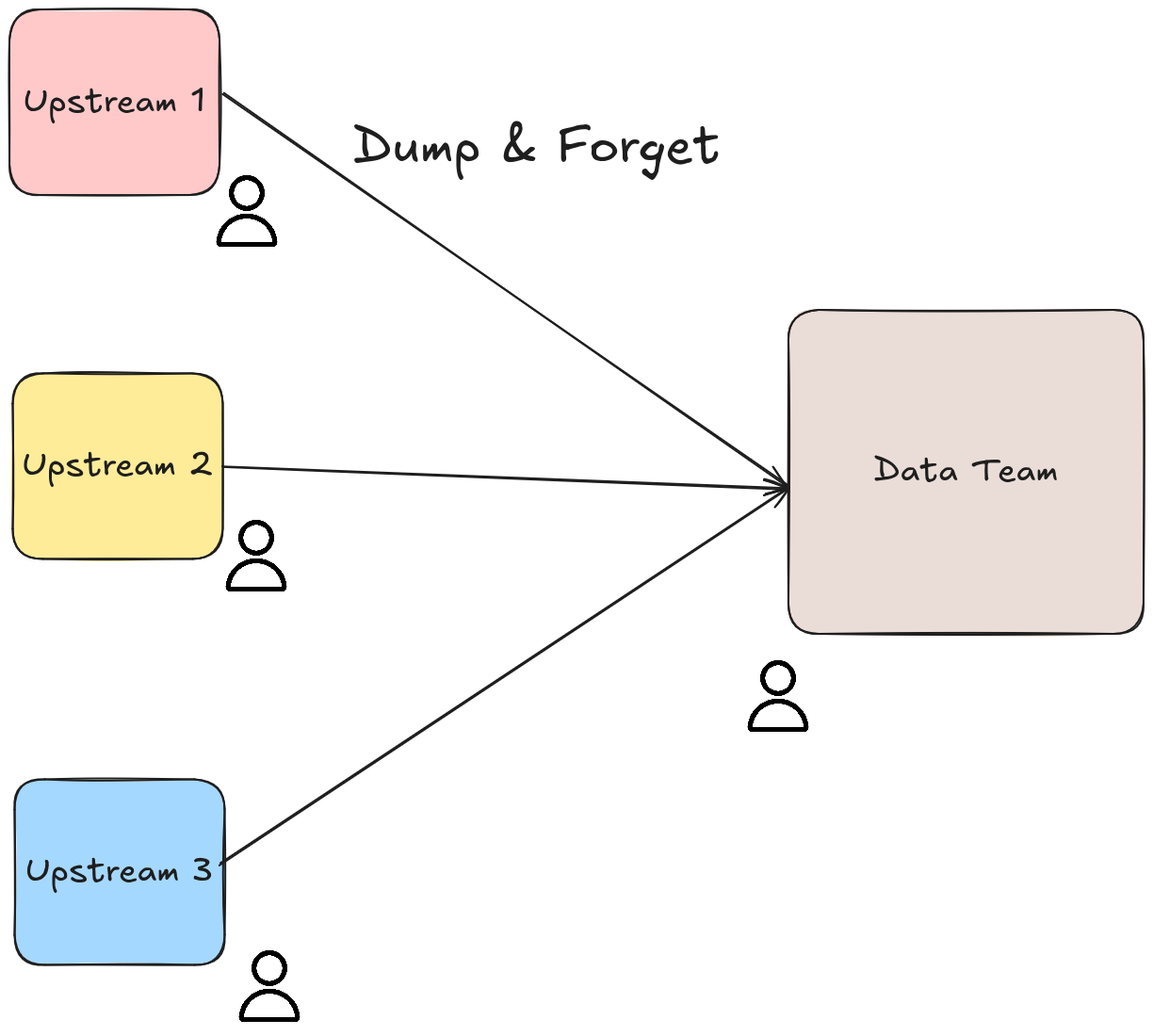 Upstream teams produce data, and the data team deals with whatever data they get. This is by far the most common method of operation in the industry.
Upstream teams produce data, and the data team deals with whatever data they get. This is by far the most common method of operation in the industry.
✅ Pros:
- Simplest approach for upstream teams
- Enables upstream teams to move fast
- Good enough for most business use cases
❌ Cons:
- The data team is constantly playing catch-up
- Bad data, breaking pipelines, & tech debt
- The data team loses conceptual knowledge of the data
🎯 How-to:
- Use Apache Iceberg and Spark’s mergeschema .
- For tools like dbt, there is generally an option to do this, e.g., on_schema_change .
2.3. The data team as upstream reviewer leads to issue prevention

In this approach, the data team is involved in the upstream’s data modeling process. Data teams are usually more pedantic about data models.
Data team reviews can prevent bad data from being produced.
✅ Pros:
- Bad data is prevented from being produced
- Well-designed data model
- Shared understanding of data between upstream and data teams
❌ Cons:
- Slow down upstream teams
- Will not catch aggregate issues, e.g., average revenue should be consistent across days
🎯 How-to:
- The process can be sped up using data contracts
- GitHub provides tools like CODEOWNERS with which upstream teams can easily include data teams in reviews
2.4. Validating input before processing saves on debug time
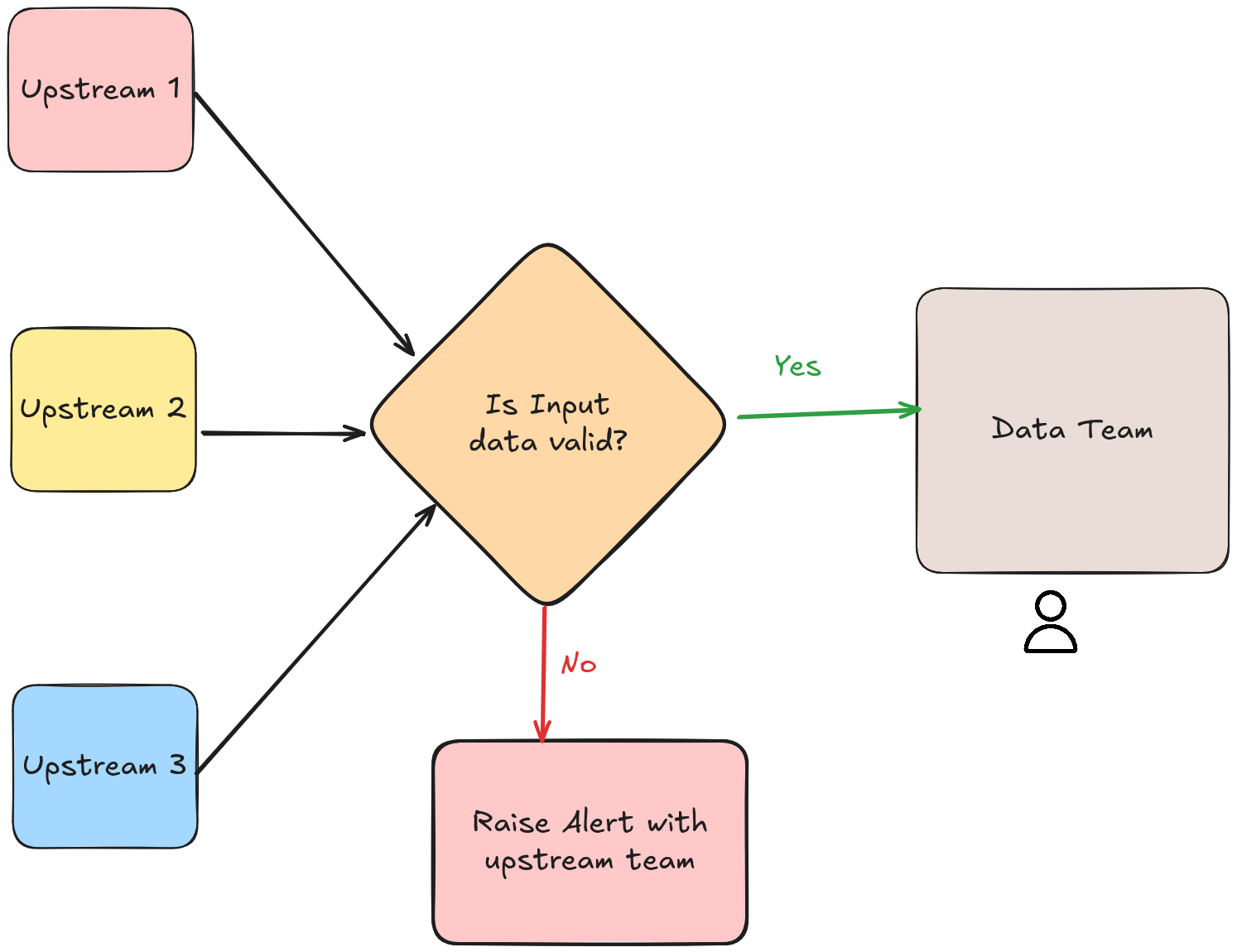
The data team checks if input data meets expectations before using it. If you find an issue with the input data, you will have to work with the upstream team to correct and reprocess the data for the time that it was inaccurate.
✅ Pros:
- Quick detection of issues
- Empowers data teams to automate issue debugging to relevant upstream teams
❌ Cons:
- Upstream & data teams need to agree on data checks
- Multiple input tests increase data processing times
🎯 How-to:
- Any data quality tool can be used to check for input DQ
- With a streaming system, you can use DLQs and reconciliation patterns
3. Conclusion
Common approaches are:
Most companies use a mix of approaches depending on the importance of the data assets to be produced.
Data teams are the connectors between upstream teams and analytics use cases, so it’s crucial to reduce friction and detect bad data.
Ideally, schema changes are handled (in order of low to high cost-to-fix)
- Before it occurs
- Before it is processed
- After the pipeline breaks during processing
- After processing by the stakeholder
Please select the option that best fits your use case. How does your team deal with changing upstream data schema? Please let me know in the comment section below.
4. Recommended reading
If you found this article helpful, share it with a friend or colleague using one of the socials below!