How to implement data quality checks with greatexpectations
- 1. Introduction
- 2. Project overview
- 3. Check your data before making it available to end-users; Write-Audit-Publish(WAP) pattern
- 4. TL;DR: How the greatexpectations library works
- 5. From an implementation perspective, there are four types of tests
- 6. Store DQ check fails and successes to see patterns
- 7. Only stop pipelines when necessary
- 8. Conclusion
- 9. Further reading
1. Introduction
Data quality checks are critical for any production pipeline. While there are many ways to implement data quality checks, the greatexpectations library is one of the popular ones. If you have wondered
How can you effectively use the greatexpectations library?
Why greatexpectations is so complex?
Why greatexpectations is so clunky and has so many moving pieces?
Then this post is for you. In this post, we will go over the key concepts you’ll need to get up and running with the greatexpectations library, along with examples of the types of tests you may run.
By the end of this post, you will have a mental model of how the greatexpectations library works and be able to quickly set up and run your own data quality checks with greatexpectations.
Recommended pre-reading: Types of data quality checks .
2. Project overview
Our project involves building a dim_customer table from raw_customer and raw_state tables. We use sqlite3 as our data warehouse. The data flow architecture is pictured below:
Code & run instructions are available here
3. Check your data before making it available to end-users; Write-Audit-Publish(WAP) pattern
To prevent consumers from accidentally using “bad” data, we should check it before making it available. The Write-Audit-Publish (WAP) pattern refers to
Write: Create the output data. This data should not be accessible by end-users but must be available for debugging in case of issues.Audit: Run DQ checks on the data from thewritestep.Publish: If the DQ checks pass, then write the data to a location (or a table) accessible by the end user.
In our code we implement the write -> audit -> publish pattern as functions here
.
Note we use the non_validated_{table_name} table to store data before running our DQ checks, and this also enables engineers to debug a dataset if a DQ check fails.
Let’s see how to do data quality checks when we create a dataset:
Read more about WAP pattern here .
4. TL;DR: How the greatexpectations library works
In greatexpectations, there are five main ideas:
Expectations: These denote what you expect from a dataset. The greatexpectations library allows us to check if the dataset meets these expectations. In our example, the expectations are defined here . This is where your define your DQ checks to be run.Validations: The results of checking if a dataset meets its expectations are called validations. The greatexpectations library allows us to capture both successes and failures. In our example, the validations are stored in the location./ecommerce/ecommerce/gx/uncommitted/validations/dim_customer_dt_created_count/__none__/and are not included as part of version control. Run the ETL pipeline atleast once to see this. We use this audit method to run the respectiveexpectation_suite(list of expectations).Data sources: define the data that greatexpectations will access. Each data source (sql db, spark, csv files, etc.) can have one or more data assets (e.g., table, dataframe, files under specific folder, etc.). In our example, we have onesqlite3data source, multiple tables, and a custom query data asset defined here . We can addbatch_metadatathat allow us to restrict the partition of each run, sort order, etc.Checkpoint: With checkpoints, you can tell greatexpectations which expectations to run, where to store the results, what actions to take after checks are run, etc. Think of it as a customizable way to define what to do, and we can tell greatexpectations to run a specific checkpoint via code. Note that we can define multiple checkpoints. We have a checkpoint defined here .Context: Think of thecontextfile as a config file that shows where the components necessary for greatexpectations are stored. We have our context defined here . The greatexpectations library uses acontextto describe the following:- Expectations storage location with
expectations_store. - Validations storage location with
validation_store. - Checkpoint storage location with
checkpoint_store. - Where to generate the output DQ webpage with
data_docs_sites.
- Expectations storage location with
In our example, we store everything locally , in a production setup, you will want to store them in an appropriate location as your architecture allows.
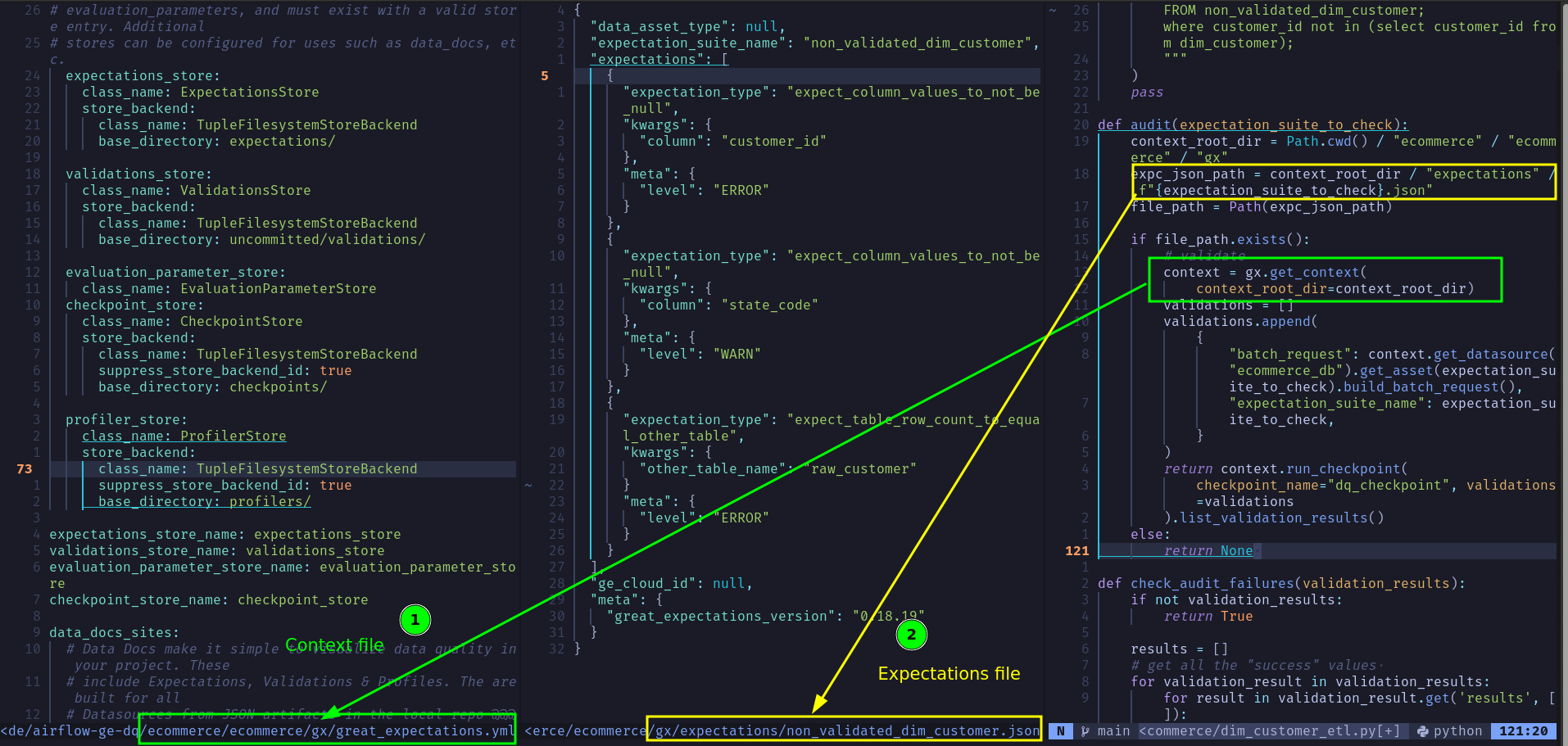
While the greatexpectations library is highly configurable (yml, json, Python, notebooks, etc.), using the above file structure has worked well as it keeps things straightforward(one expectation suite per dataset called as part of the pipeline).
4.1. greatexpectations quick setup
While the project has greatexpectations setup at gx folder, setting up a new one is relatively straightforward.
- Create a context with Python interactively: instruction link . By default, all the stores are set to the local filesystem; change it as needed.
- Define a datasource. Since we use
sqlite3as the execution engine, use this instruction link to define your sqlite3 datasource. Note that we have created a data assets for each table and query . - Use the expectations list documentation to define your expectations interactively with Python: instructions list
5. From an implementation perspective, there are four types of tests
While there are a lot of types data quality checks , when implemented, they fall into one of these four types:
5.1. Running checks on one dataset
These types of checks are the most common and are run on the dataset before being made available to downstream consumers. In our project these checks that check for nulls are examples of this type of checks.
5.2. Checks involving the current dataset and its historical data
These types of checks are used to check the distribution of a column (or a metric) over time. Commonly used as part of anomaly detection, you may want to compute a specific metric based on historical data and compare it to the current metric.
An example of this is the count distribution check in our project. We use a query data asset to create the count metric
and then check that its z-score is within +3 to -3 using this expectation
.
5.3. Checks involving comparing datasets
These types of checks are used to reconcile output and input datasets and help ensure that no erroneous joins/filters caused duplicate rows or resulted in removing valid rows.
In our project, we check that the output dim_customer has the same number of customers as the input raw_customer, using this expectation
.
5.4. Checks involving custom query
When your tests are complex, you must write a custom query(or custom dataframe joins). In our project, we use a custom query to get a count of rows; we can do this using a query type data asset .
6. Store DQ check fails and successes to see patterns
The greatexpectations library logs detailed results of the dq checks that it ran to the validation store. Storing and analyzing this information is crucial since it allows us to see patterns in DQ failures.
For example, Are you noticing a lot of input data set failures? Check with the upstream team to fix this. Are you noticing a lot of output layer DQ failures? Spend time cleaning up the code to avoid issues.
7. Only stop pipelines when necessary
Most companies have varying levels of severity .
In our code, we define this as part of the meta field in the expectation
and use this check_audit_failure
method to handle this. If we are sending alerts to a 3rd party system like pagerduty, greatexpectations enables us to set severity directly via the API
.
8. Conclusion
To recap, we saw
- How greatexpectations work and how to set them up .
- The four types of tests, from an implementation perspective .
- Logging DQ check results and severity levels of DQ checks .
While the greatexpectations library can seem overwhelming, it is incredibly powerful. If you are stuck at implementing your DQ checks with greatexpectations, use this post as your guide; if you still have questions, email me at joseph.machado@startdataengineering.com or leave a comment below.
9. Further reading
- GH issues for greatexpectations
- greatexpectation docs
- Types of data quality checks
- How to add tests to your data pipeline
If you found this article helpful, share it with a friend or colleague using one of the socials below!