25 SQL tips to level up your data engineering skills
- Introduction
- Setup
- SQL tips
- 1. Handy functions for common data processing scenarios
- 1.1. Need to filter on WINDOW function without CTE/Subquery use QUALIFY
- 1.2. Need the first/last row in a partition, use DISTINCT ON
- 1.3. STRUCT data types are sorted based on their keys from left to right
- 1.4. Get the first/last element with ROW_NUMBER() + QUALIFY
- 1.5. Check if at least one or all boolean values are true with BOOL_OR & BOOL_AND respectively
- 1.6. If you want to select all columns except a few, use EXCLUDE
- 1.7. Tired of creating a long list of columns from GROUP BY, use GROUP BY ALL
- 1.8. Need only to count rows meeting a specific condition? Use COUNT_IF
- 1.9. Need to concatenate rows of string after GROUP BY? Use STRING_AGG
- 1.10. Handle Null column values with other columns or fallback values using COALESCE
- 1.11. Generate a range of number/date rows with GENERATE_SERIES
- 1.12. Convert ARRAY/LIST of elements to individual rows with UNNEST
- 2. Get rows in one table depending on its presence/absence in another with SET operations
- 3. Create reusable functions in SQL
- 4. Dynamically generate SQL with Python
- 5. Access data about your data (aka metadata)
- 6. Avoid data duplicates with UPSERTS (aka MERGE INTO)
- 7. Advanced JOIN types
- 8. Business use cases
- 1. Handy functions for common data processing scenarios
- Conclusion
- Continue reading
Introduction
As a data engineer, you always want to uplevel yourself. SQL is the bread and butter of data engineering. Whether you are a seasoned pro or new to data engineering, there is always a way to improve your SQL skills. Do you ever think:
I wish I had known this SQL feature sooner
I wish “learn SQL” online got into more interesting depths of the dialect than the basic shit it always is
I wish I had known this sooner; it’s a much simpler way to use window functions for filtering; no more nested queries
I wish I didn’t have to pull data into Python to do some loops
This post is for you. Imagine being proficient in data processing patterns in SQL in addition to the standard functions. You will be able to write easy-to-maintain, clean, and scalable SQL.
This post will review eight patterns to help you write easy-to-maintain SQL code and uplevel your SQL skills.
Setup
We will use the tpch data for data. The TPC-H data represents a car parts seller’s data warehouse, where we record orders, items that make up that order (lineitem), supplier, customer, part (parts sold), region, nation, and partsupp (parts supplier).

You can run the code on GitHub codespaces, by following this link & then going to ./concepts/sql_tips/sql_tips.ipynb .
You can also run the code locally using the following commands:
git clone https://github.com/josephmachado/adv_data_transformation_in_sql.git
cd adv_data_transformation_in_sql
python -m venv ./env # create a virtual env
source env/bin/activate # use virtual environment
pip install -r requirements.txt
python setup.py
jupyter lab
And going to ./concepts/sql_tips/sql_tips.ipynb ..
Prerequisites:
SQL tips
1. Handy functions for common data processing scenarios
1.1. Need to filter on WINDOW function without CTE/Subquery use QUALIFY
SELECT
o_orderkey,
o_totalprice,
RANK() OVER (ORDER BY o_totalprice DESC) AS price_rank
FROM orders
QUALIFY price_rank <= 10;
This query ranks the orders by o_totalprice in descending order and filters the top 10 using the QUALIFY clause. Without QUALIFY, we would have to use a subquery or CTE approach to filter on price_rank.
1.2. Need the first/last row in a partition, use DISTINCT ON
SELECT DISTINCT ON (o_custkey)
o_custkey,
o_orderdate,
o_totalprice
FROM orders
ORDER BY o_custkey, o_orderdate DESC;
DISTINCT ON (o_custkey) ensures you get only one row per customer (o_custkey). The ORDER BY o_custkey, o_orderdate DESC clause ensures that the query returns the most recent order (o_orderdate) for each customer based on the latest order date.
DISTINCT ON(o_custkey) will return the most recent order details (like o_totalprice and o_orderdate) for each customer (o_custkey).
1.3. STRUCT data types are sorted based on their keys from left to right
WITH order_struct AS (
SELECT
o_orderkey,
STRUCT_PACK(o_orderdate, o_totalprice, o_orderkey) AS order_info
FROM orders
)
SELECT
MIN(order_info) AS min_order_date,
MAX(order_info) AS max_order_date_price
FROM order_struct;
In the above example, the order_info struct will be sorted based on o_orderdate, o_totalprice, and o_orderkey in that order. If two order_info have the same o_orderdate, then o_totalprice will be used to determine the order.
1.4. Get the first/last element with ROW_NUMBER() + QUALIFY
SELECT
o_custkey,
o_orderdate,
o_totalprice,
ROW_NUMBER() OVER (PARTITION BY o_custkey ORDER BY o_orderdate DESC) AS rn
FROM orders
QUALIFY rn = 1;
In the above example, we partition the data by o_custkey and rank them in descending order of o_orderdate.
1.5. Check if at least one or all boolean values are true with BOOL_OR & BOOL_AND respectively
SELECT
o_custkey,
BOOL_OR(cast(o_shippriority as boolean)) AS has_atleast_one_priority_order,
BOOL_AND(cast(o_shippriority as boolean)) AS has_all_priority_order
FROM orders
GROUP BY o_custkey;
Explanation:
BOOL_OR(o_ispriority): This aggregate function checks whether at least one of the orders for a customer (o_custkey) has aTRUEvalue in theo_isprioritycolumn.BOOL_AND(o_ispriority): This aggregate function checks whether all of the orders for a customer (o_custkey) have aTRUEvalue in theo_isprioritycolumn.
1.6. If you want to select all columns except a few, use EXCLUDE
SELECT * EXCLUDE (o_orderdate, o_totalprice)
FROM orders;
SELECT * EXCLUDE (o_orderdate, o_totalprice): This syntax selects all columns from the orders table except the specified columns (o_orderdate and o_totalprice).
1.7. Tired of creating a long list of columns from GROUP BY, use GROUP BY ALL
SELECT
o_orderkey,
o_custkey,
o_orderstatus,
SUM(o_totalprice) AS total_price
FROM orders
GROUP BY ALL;
Explanation:
GROUP BY ALL: This automatically groups by all non-aggregated columns in theSELECTstatement (in this case,o_orderkey,o_custkey, ando_orderstatus).SUM(o_totalprice): This is the aggregated column, so DuckDB will group by the remaining columns without you needing to list them explicitly.
Using GROUP BY ALL prevents errors where you might forget to include one or more non-aggregated columns in the GROUP BY clause, making your SQL query more concise and less error-prone.
This feature is particularly useful in queries with many columns, where manually writing out all group-by columns can become tedious and prone to mistakes.
1.8. Need only to count rows meeting a specific condition? Use COUNT_IF
SELECT
o_custkey,
COUNT_IF(o_totalprice > 100000) AS high_value_orders,
COUNT(o_totalprice) as all_orders
FROM orders
GROUP BY o_custkey;
This query groups by o_custkey and counts the number of orders for each customer with a total price greater than 100,000.
This powerful function simplifies counting conditional occurrences in SQL. Without COUNT_IF, you’d have to use SUM(CASE WHEN o_totalprice > 100000 THEN 1 ELSE 0 END).
1.9. Need to concatenate rows of string after GROUP BY? Use STRING_AGG
SELECT STRING_AGG(c_name, ', ') AS customer_names
FROM customer;
This query uses STRING_AGG in DuckDB to concatenate all the values from the c_name column in the customer table into a single string, separated by commas (, ), and returns it as customer_names.
1.10. Handle Null column values with other columns or fallback values using COALESCE
WITH fake_orders AS (
SELECT 1 AS o_orderkey, 100 AS o_totalprice, NULL AS discount
UNION ALL
SELECT 2 AS o_orderkey, 200 AS o_totalprice, 20 AS discount
UNION ALL
SELECT 3 AS o_orderkey, 300 AS o_totalprice, NULL AS discount
)
SELECT
o_orderkey,
o_totalprice,
discount,
COALESCE(discount, o_totalprice * 0.10) AS final_discount
FROM fake_orders;
Explanation:
- COALESCE: This function returns the first non-NULL value from a list of arguments.
- In this example, if
discountis NULL for any row,COALESCEreplaces it witho_totalprice * 0.10. Otherwise, it returns adiscount.
Use Case for COALESCE:
- Handling NULL Values: When working with columns that may have NULL values,
COALESCEcan substitute them with a default value (e.g.,0,'', or a custom calculation).COALESCEis particularly useful in financial calculations, reports, or data cleaning where NULL values need to be replaced with meaningful defaults to avoid errors or incorrect results. - Fallback Values: It provides query fallback options, returning alternative values if the primary value is NULL.
1.11. Generate a range of number/date rows with GENERATE_SERIES
SELECT *
FROM generate_series(1, 10);
SELECT *
FROM generate_series('2024-01-01'::DATE, '2024-01-10'::DATE, INTERVAL 1 DAY);
Explanation:
generate_series(1, 10): This function generates a series of numbers from 1 to 10. Each number in the range is output as a separate row.- The result will be a table with a single column of integers from 1 to 10.
Use Case:
- Data Simulation:
generate_seriesis often used to create a sequence of numbers for testing or simulating data (e.g., generating dates, IDs, or time intervals). - Joining with Other Tables: You can use
generate_seriesto produce rows that can be joined with other tables, for example, to fill in missing dates or create data sequences where needed. - Looping/Iteration: This technique is useful when you need to perform actions over a range of values, like generating monthly or yearly reports for a range of dates.
1.12. Convert ARRAY/LIST of elements to individual rows with UNNEST
WITH nested_data AS (
SELECT 1 AS id, [10, 20, 30] AS values
UNION ALL
SELECT 2 AS id, [40, 50] AS values
)
SELECT
id,
UNNEST(values) AS flattened_value
FROM nested_data;
Explanation:
- UNNEST(values): The UNNEST function takes the array in the values column and returns one row for each element in the array.
Use Case for UNNEST:
- Nested Arrays: Often used with semi-structured data like JSON arrays or nested lists, you need to process each item in the array individually.
2. Get rows in one table depending on its presence/absence in another with SET operations
2.1. Get data from a table based on the existence of data in another with EXISTS
SELECT
c_custkey,
c_name
FROM customer
WHERE EXISTS (
SELECT o_orderkey
FROM orders
WHERE o_totalprice > 5000000
-- o_custkey = c_custkey -- replace the above filter with this => Does the customer from the customer table have at least one order?
);
The query returns customers with at least one order whose o_totalprice exceeds 5,000,000.
The EXISTS operator tests for the existence of any row inside the subquery. It returns true when the subquery returns one or more records and false otherwise.
2.2. Get data that is present in both the tables with INTERSECT
SELECT c_custkey
FROM customer
INTERSECT
SELECT o_custkey
FROM orders;
The query returns customers (c_custkey) who appear in both the customer and orders tables.
2.3. Get data that is present in Table 1 but not in Table 2 with EXCEPT
SELECT c_custkey
FROM customer
EXCEPT
SELECT o_custkey
FROM orders;
The query returns customers (c_custkey) present in the customer table but without corresponding records in the orders table. The EXCEPT operator removes rows that have matches in the second query.
2.4. Get data diff (aka delta), with (A - B) U (B - A)
-- ASSUME cust_test is the customer data's next data load
DROP TABLE IF EXISTS cust_test;
-- 1. Create cust_test table from customer
CREATE TABLE cust_test AS SELECT * FROM customer;
-- 2. Append a new row to cust_test
-- Insert a new row with values for all columns
INSERT INTO cust_test VALUES (9999, 'New Customer', 'new_customer@example.com', '123', '2024-10-21', 10.00, 'ExtraColumn2', 'ExtraColumn3');
-- 3. Delete a row from cust_test (delete where customer_id = 2)
DELETE FROM cust_test WHERE c_custkey = 2;
-- 4. Update a row in cust_test (update customer with customer_id = 1)
UPDATE cust_test
SET c_name = 'Updated Name', c_address = 'updated address'
WHERE c_custkey = 1;
SELECT c_custkey, 'DELETED' as ops FROM (
SELECT c_custkey
FROM customer
EXCEPT
SELECT c_custkey
FROM cust_test)
UNION ALL
SELECT c_custkey, 'UPSERTED' as ops FROM (
SELECT c_custkey, c_name, c_address
FROM cust_test
EXCEPT
SELECT c_custkey, c_name, c_address
FROM customer)
3. Create reusable functions in SQL
3.1. Functions in SQL are called MACROs
CREATE MACRO percentage(numerator, denominator) AS (
(CAST(numerator AS DOUBLE) / CAST(denominator AS DOUBLE)) * 100
);
SELECT o_orderkey, o_totalprice, percentage(o_totalprice, 50000) AS discount_percentage
FROM orders
LIMIT 5;
Explanation:
- The macro
percentagetakes two parameters,numeratoranddenominator, and returns the percentage calculation. - In this case, it calculates the percentage of
o_totalpriceagainst a constant value (50,000). - The macro is used as a function but expanded inline when executing the query.
CREATE MACRO large_order(order_price) AS (
CASE
WHEN order_price > 100000 THEN 'Large Order'
ELSE 'Regular Order'
END
);
SELECT o_orderkey, o_totalprice, large_order(o_totalprice) AS order_type
FROM orders
LIMIT 5;
Summary:
- SQL Macros are helpful for encapsulating reusable SQL expressions, similar to functions in other programming languages.
- They allow you to abstract complex logic and reuse it in different parts of your query, improving both readability and maintainability.
- DuckDB macros are inline, meaning they are expanded at query execution time, which avoids the overhead of function calls.
4. Dynamically generate SQL with Python
4.1. Use Jinja2 to create SQL queries in Python
from jinja2 import Template
# Define a Jinja2 SQL template with a loop
sql_template = """
SELECT o_orderkey, o_custkey, o_totalprice
FROM orders
WHERE o_totalprice > {{ price_threshold }}
{% if customer_keys %}
AND o_custkey IN (
{% for custkey in customer_keys %}
{{ custkey }}{% if not loop.last %}, {% endif %}
{% endfor %}
)
{% endif %}
ORDER BY o_totalprice DESC;
"""
# Render the template with dynamic parameters
template = Template(sql_template)
# Parameters to be passed to the template
params = {
"price_threshold": 20000,
"customer_keys": [1001, 1002, 1003] # A list of customer keys to filter on
}
# Render the SQL query (do not execute, just generate SQL)
rendered_sql = template.render(params)
# Output the generated SQL
print("Generated SQL Query:")
print("====================")
print(rendered_sql)
Explanation:
- Jinja2 Loop: The
{% for custkey in customer_keys %}loop dynamically generates theINclause, listing the customer keys separated by commas. - Conditional Logic: The
{% if customer_keys %}block ensures that theINclause is only added if thecustomer_keyslist is not empty. loop.last: This Jinja2 variable avoids adding a comma after the last item in the list.
5. Access data about your data (aka metadata)
See your DB documentation to see where this data is stored. For DuckDB checkout their docs here .
5.1. Databases store metadata in information_schema
-- Information about our tables is stored here
SELECT schema_name,
view_name
FROM duckdb_views();
SELECT * FROM information_schema.tables;
-- Database-level settings
SELECT * FROM duckdb_settings();
-- List of all tables in our DuckDB
SELECT schema_name,
table_name
FROM duckdb_tables();
6. Avoid data duplicates with UPSERTS (aka MERGE INTO)
6.1. Insert new data, Update existing data in a table with UPSERT/MERGE INTO
DROP TABLE IF EXISTS dim_customer_scd2;
-- Create a Slowly Changing Dimension (SCD Type 2) table for customer
CREATE TABLE dim_customer_scd2 (
c_custkey INTEGER PRIMARY KEY,
c_name VARCHAR,
c_address VARCHAR,
c_nationkey INTEGER,
c_phone VARCHAR,
c_acctbal DOUBLE,
c_mktsegment VARCHAR,
c_comment VARCHAR,
valid_from DATE,
valid_to DATE,
is_current BOOLEAN
);
-- Insert current data from the TPCH customer table into the SCD2 table
INSERT INTO dim_customer_scd2
SELECT
c_custkey,
c_name,
c_address,
c_nationkey,
c_phone,
c_acctbal,
c_mktsegment,
c_comment,
'2024-10-17' AS valid_from,
NULL AS valid_to, -- NULL means it's the current active record
TRUE AS is_current
FROM customer;
SELECT * FROM dim_customer_scd2 ORDER BY c_custkey DESC LIMIT 2;
INSERT INTO dim_customer_scd2 (
c_custkey,
c_name,
c_address,
c_nationkey,
c_phone,
c_acctbal,
c_mktsegment,
c_comment,
valid_from,
valid_to,
is_current
)
VALUES
(1, 'Customer#000000001', 'New Address 1', 15, '25-989-741-2988', 711.56, 'BUILDING', 'comment1', '2024-10-18', NULL, TRUE),
(2, 'Customer#000000002', 'New Address 2', 18, '12-423-790-3665', 879.49, 'FURNITURE', 'comment2', '2024-10-18', NULL, TRUE),
(1501, 'Customer#000001501', 'New Address 1501', 24, '11-345-678-9012', 500.50, 'MACHINERY', 'comment1501', '2024-10-18', NULL, TRUE),
(1502, 'Customer#000001502', 'New Address 1502', 21, '22-456-789-0123', 600.75, 'AUTOMOBILE', 'comment1502', '2024-10-18', NULL, TRUE)
ON CONFLICT (c_custkey) DO
-- Handle existing customers (Customer#000000001 and Customer#000000002) for SCD Type 2
UPDATE SET valid_to = EXCLUDED.valid_from, is_current = FALSE
WHERE dim_customer_scd2.c_custkey = EXCLUDED.c_custkey AND dim_customer_scd2.is_current = TRUE;
SELECT * FROM dim_customer_scd2
WHERE c_custkey IN (1,2,1501,1502)
ORDER BY c_custkey;
In the above example, we can see that we create an SCD2 table and UPSERT new data into it using UPSERT.
Note: Some DBs have INSERT..ON CONFLICT and some have access to MERGE INTO.. Check your DB/Table format documentation for details.
7. Advanced JOIN types
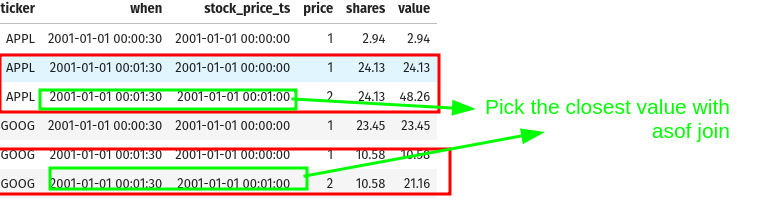
7.1. Get the value from Table1 that is closest (in time) to Table2’s row with ASOF JOIN
WITH stock_prices AS (
SELECT 'APPL' AS ticker, TIMESTAMP' 2001-01-01 00:00:00' AS "when", 1 AS price
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:01:00', 2
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:02:00', 3
UNION ALL
SELECT 'MSFT', TIMESTAMP' 2001-01-01 00:00:00', 1
UNION ALL
SELECT 'MSFT', TIMESTAMP' 2001-01-01 00:01:00', 2
UNION ALL
SELECT 'MSFT', TIMESTAMP' 2001-01-01 00:02:00', 3
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:00:00', 1
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:01:00', 2
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:02:00', 3
),
portfolio_holdings AS (
SELECT 'APPL' AS ticker, TIMESTAMP' 2000-12-31 23:59:30' AS "when", 5.16 AS shares
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:00:30', 2.94
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:01:30', 24.13
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2000-12-31 23:59:30', 9.33
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:00:30', 23.45
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:01:30', 10.58
UNION ALL
SELECT 'DATA', TIMESTAMP' 2000-12-31 23:59:30', 6.65
UNION ALL
SELECT 'DATA', TIMESTAMP' 2001-01-01 00:00:30', 17.95
UNION ALL
SELECT 'DATA', TIMESTAMP' 2001-01-01 00:01:30', 18.37
)
SELECT h.ticker,
h.when,
p.when AS stock_price_ts,
price,
shares,
price * shares AS value
FROM portfolio_holdings h
ASOF JOIN stock_prices p
ON h.ticker = p.ticker
AND h.when >= p.when
ORDER BY 1, 2;
AsOf joins are used to find the value of a varying property at a specific point in time. This use case is so common that it is where the name came from:
Give me the value of the property as of this time.
In the above example, note that even though rows in portfolio_holdings match with multiple rows in stock_prices, we only pick the row from stock_prices that is closest (in time) to the row in portfolio_holdings.
We can do the same without an asof join, as shown below:
WITH stock_prices AS (
SELECT 'APPL' AS ticker, TIMESTAMP' 2001-01-01 00:00:00' AS "when", 1 AS price
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:01:00', 2
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:02:00', 3
UNION ALL
SELECT 'MSFT', TIMESTAMP' 2001-01-01 00:00:00', 1
UNION ALL
SELECT 'MSFT', TIMESTAMP' 2001-01-01 00:01:00', 2
UNION ALL
SELECT 'MSFT', TIMESTAMP' 2001-01-01 00:02:00', 3
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:00:00', 1
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:01:00', 2
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:02:00', 3
),
portfolio_holdings AS (
SELECT 'APPL' AS ticker, TIMESTAMP' 2000-12-31 23:59:30' AS "when", 5.16 AS shares
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:00:30', 2.94
UNION ALL
SELECT 'APPL', TIMESTAMP' 2001-01-01 00:01:30', 24.13
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2000-12-31 23:59:30', 9.33
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:00:30', 23.45
UNION ALL
SELECT 'GOOG', TIMESTAMP' 2001-01-01 00:01:30', 10.58
UNION ALL
SELECT 'DATA', TIMESTAMP' 2000-12-31 23:59:30', 6.65
UNION ALL
SELECT 'DATA', TIMESTAMP' 2001-01-01 00:00:30', 17.95
UNION ALL
SELECT 'DATA', TIMESTAMP' 2001-01-01 00:01:30', 18.37
)
SELECT h.ticker,
h.when,
p.when as stock_price_ts,
price,
shares,
price * shares AS value
FROM portfolio_holdings h
JOIN stock_prices p
ON h.ticker = p.ticker
AND h.when >= p.when
ORDER BY 1, 2;
We must use Windows to filter out data if we do not use the asof join.
7.2. Get rows in table1 that are not in table2 with ANTI JOIN
SELECT c.c_custkey
FROM customer c
LEFT JOIN orders o
ON c.c_custkey = o.o_custkey
WHERE o.o_custkey IS NULL
ORDER BY c.c_custkey
LIMIT 5;
-- Some DBs have inbuilt support for left anti-join
SELECT c.c_custkey
FROM customer c
ANTI JOIN orders o
ON c.c_custkey = o.o_custkey
ORDER BY c.c_custkey
LIMIT 5;
7.3. For every row in table1 join with all the “matching” rows in table2 with LATERAL JOIN
SELECT
o.o_orderkey,
o.o_totalprice,
l.l_linenumber,
l.l_extendedprice
FROM orders o,
LATERAL (
SELECT l.l_linenumber,
l_extendedprice
FROM lineitem l
WHERE l.l_orderkey = o.o_orderkey
AND l.l_linenumber <= 2
AND l.l_extendedprice < (o.o_totalprice / 2)
) AS l
ORDER BY 1, 3;
For each row in the orders table (o'), the subquery in the LATERAL JOIN selects line items (l`) that match certain conditions.
SELECT *
FROM range(3) t(i), LATERAL (SELECT i + 1) t2(j);
SELECT
o.o_orderkey,
o.o_totalprice,
l.lineitem_count
FROM orders o,
LATERAL (
SELECT COUNT(*) AS lineitem_count
FROM lineitem l
WHERE l.l_orderkey = o.o_orderkey
) AS l;
For each row in the orders table (o'), the subquery in the LATERAL JOIN counts the number of line items (lineitem_count`) related to that order.
8. Business use cases
8.1. Change dimension values to individual columns with PIVOT
SELECT
o_custkey,
SUM(CASE WHEN o_orderstatus = 'F' THEN o_totalprice ELSE 0 END) AS fulfilled_total,
SUM(CASE WHEN o_orderstatus = 'O' THEN o_totalprice ELSE 0 END) AS open_total,
SUM(CASE WHEN o_orderstatus = 'P' THEN o_totalprice ELSE 0 END) AS pending_total
FROM orders
GROUP BY o_custkey
ORDER BY o_custkey;
Explanation:
SUM(CASE WHEN o_orderstatus = 'F' THEN o_totalprice ELSE 0 END): This sums up theo_totalpricefor orders that have a status of'F'(Fulfilled) for each customer (o_custkey).- Similarly, we apply this for other statuses like
'O'(Open) and'P'(Pending) to pivot the data byo_orderstatus. GROUP BY o_custkey: Groups the data by each customer to aggregate the total prices based on order status.
-- some DBs have support for PIVOT
FROM orders
PIVOT (
sum(o_totalprice)
FOR
o_orderstatus IN ('F', 'O', 'P')
GROUP BY o_custkey
)
ORDER BY o_custkey;
8.2. Generate metrics for every possible combination of dimensions with CUBE
SELECT
o_orderpriority,
o_orderstatus,
EXTRACT(YEAR FROM o_orderdate) AS order_year,
SUM(o_totalprice) AS total_sales
FROM orders
GROUP BY CUBE (o_orderpriority, o_orderstatus, order_year)
ORDER BY 1,2,3;
Explanation:
CUBE (o_orderpriority, o_orderstatus, order_year): This will group the data and calculate subtotals and grand totals for all possible combinations ofo_orderpriority,o_orderstatus, andorder_year.- It will generate all combinations of the grouping columns, including:
- Grouping by just
o_orderpriority - Grouping by just
o_orderstatus - Grouping by just
order_year - Grouping all three together
- Grouping by pairs of columns
- A grand total (no grouping by any column)
- Grouping by just
SUM(o_totalprice)sums the total order price for each combination of groupings.
Use Case:
- OLAP Reporting: CUBE is commonly used in OLAP scenarios where you must analyze data from multiple perspectives. For instance, generate reports showing total sales by order priority, status, year, and possible combinations of these dimensions.
- Sales Analysis: In sales analysis, CUBE can help create pivot-like summaries that show how different attributes (e.g., priority, status, time period) contribute to the overall sales.
- Financial Reports: Financial departments often use CUBE to calculate totals and subtotals across dimensions like departments, periods, and account categories, making it easier to prepare comprehensive financial reports.
CUBE is a powerful tool for producing multidimensional data summaries in one go, helping with complex reporting and data analysis tasks.
Conclusion
To recap, we saw
- Handy functions for common data processing scenarios
- Get rows in one table depending on its presence/absence in another with SET operations
- Create reusable functions in SQL
- Dynamically generate SQL with Python
- Access data about your data (aka metadata)
- Avoid data duplicates with UPSERTS (aka MERGE INTO)
- Advanced JOIN types
- SQL for Business use cases
Next time you see a particularly complex SQL, check this post to see if you solve it in SQL using the available functions/data processing patterns. More often than not, you will be surprised by how versatile SQL can be.
Please let me know in the comment section below if you have any questions or comments.
Continue reading
- SQL for data engineers
- SQL or Python for data processing
- dbt tutorial
- Build a data project with step-by-step instructions
If you found this article helpful, share it with a friend or colleague using one of the socials below!
This is a large but top article, great summarizing some of the new advanced SQL features.
Thank you! Yea I wanted to keep it shorter, but felt like I needed this much to cover the 8 patterns.