What are the Key Parts of Data Engineering?
1. Introduction
If you are trying to break into (or land a new) data engineering job, you will inevitably encounter a slew of data engineering tools. The list of tools/frameworks to know can be overwhelming. If you are wondering
What are the parts of data engineering?
Which parts of data engineering are the most important?
Which popular tools should you focus your learning on?
How to build portfolio projects?
Then this post is for you. This post will review the critical components of data engineering and how you can combine them.
By the end of this post, you will know all the critical components necessary for building a data pipeline.
2. Key parts of data systems:
Most data engineering tool falls into one of the parts shown below:
For a better view: Right click on the image below -> Open Image in New Tab
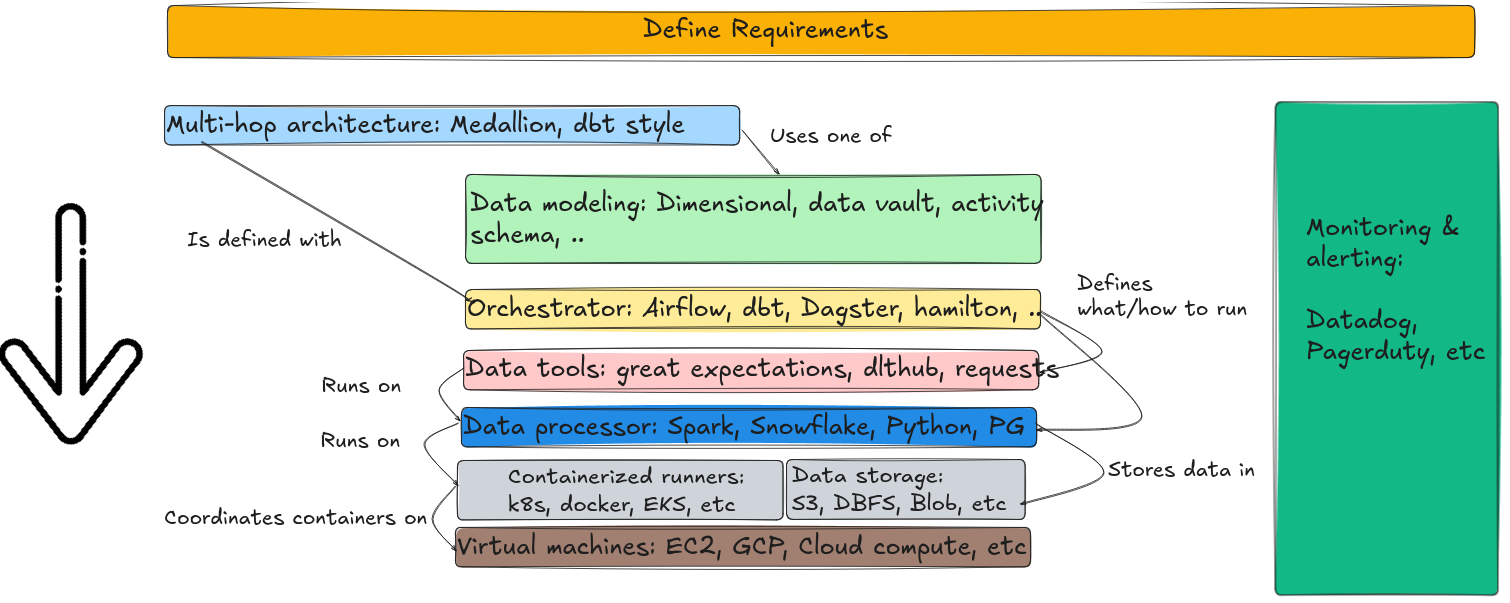
The above image represents the parts of building a data pipeline and the order of priority. From the above image, we can see that the highest priority is defining the requirements, data flow, data model, etc.
The idea is that the higher priority items need a lot of effort to get right as these are harder (compared to lower priority items) to change.
Note This article assumes that you can communicate and evangelize the results of your data pipeline.
2.1. Requirements
Always start with defining clear requirements. Having clear requirements will ensure that your end-users get what they need.
Read How to gather requirements for your data pipeline for a detailed guide on requirement gathering.
Typically, the end-users will have some input on the data quality checks needed in this stage. As you build the pipeline, you must usually add more data quality checks. Read this guide on how to define data quality checks .
2.2. Data flow design
Once you have the requirements, you should define how the data flows through your system. This step will involve deciding
- The multi-hop architecture (medallion/dbt style)
- The data model to use (Kimball, data vault, activity schemas, etc)
Read Using standard patterns to progressively transform data for a detailed guide on how to do this.
2.3. Orchestrator and scheduler
Use an orchestrator to define the parts of your data flow. Depending on your use case, you may restrict the data flow across multiple DAGs or a single DAG.
Use a scheduler to define how often the pipeline should run; the requirements will explain this.
Read this article: Why use an orchestrator to learn more about how orchestrators help turn your data flow design into data pipeline code.
Examples: Airflow
, Dagster
, dbt (orchestrator)
, Hamilton (orchestrator)
, etc
2.4. Data processing design
You will use the data flow design and write the necessary code at this stage. You will:
- Choose the data processor for your use case (Spark, Snowflake, DuckDB, native Python, etc.).
- Define how to pull data from source systems.
- Implement data quality checks that defined in the requirements phase.
You will use your distributed data processing system knowledge to create resilient and effective pipelines at this stage.
Examples: Spark
, Snowflake
, DuckDB
, Polars
, Flink
, Kafka
, Trino
, Python
, etc
2.5. Code organization
With the data processing system defined, you can follow coding best practices to ensure that your code is easy to maintain and debuggable.
Read these guides on How to write good data pipeline code and Coding patterns in Python for a detailed guide on this topic.
2.6. Data storage design
In data warehouse systems, data reads are more common than data processing. Due to the read-heavy nature of data use, we should ensure that the data is stored efficiently for reads.
You will use the requirements (query per second, common filters, etc.) and knowledge of data storage patterns like partitioning, clustering, and table/file formats to store the datasets that downstream users will use appropriately.
Read this guide on How to store data for better performance .
Examples: AWS S3
, GCP Cloud store
, etc
2.7. Monitoring & Alerting
Monitoring and alerting are crucial to ensure continued use of your data. You will need to define the metrics to monitor and define thresholds, which will send an alert to the end-user/on-call engineer.
Read this short guide on how to think about monitoring for data pipelines and this on How to define and manage sound alerts .
Examples: Datadog
, Pagerduty
, Papertrail
, etc
2.8. Infrastructure
The DevOps team typically handles this part, but it’s good to know. Most companies use containers to run their pipelines.
Read this guide on How to use docker and docker compose and how to get started with CI .
Examples: Docker
, Terraform
, Kubernetes
, etc
3. Conclusion
To recap, we saw how to
- Gathering requirements
- Design Data flow
- Orchestrate and schedule pipelines
- Desing how to process data
- Organize code
- Design data storage
- Set up Monitoring & Alerting
- Setup Infrastructure
Remember to clearly define the higher-priority items before the lower-priority ones (e.g., know your data’s latency requirement before thinking about how to optimize the pipeline).
Use this pattern to create data pipelines quickly. While you may need to skip some steps (due to unavailability of information, timelines, etc.), following the above order will ensure that your pipeline delivers and the end-users are satisfied.
If you found this article helpful, share it with a friend or colleague using one of the socials below!
Spot on. Great overview of Data Engineering.
Amazing! Thanks for the great content!