Why use Apache Airflow (or any orchestrator)?
- 1. Introduction
- 2. Features crucial to building and maintaining data pipelines
- 3. Conclusion
- 4. Further reading
1. Introduction
Are you trying to understand why someone would use a system like Airflow (or Dagster) to run simple scripts? If you are wondering
Why do we need this tool instead of a simple plain-python request?
What benefits does Airflow (and other orchestrators) provide?
Then this post is for you. Understanding the needs of complex data pipelines can help you understand the need for a tool like Airflow. This post will cover the three main concepts of running data pipelines: scheduling, orchestration, and Observability.
In this post we will use Beginner DE Project as an example to explain concepts.
2. Features crucial to building and maintaining data pipelines
Let’s look at the key features essential for most data pipelines and explore how Apache Airflow enables data engineers to do these.
We will go over how Apache Airflow:
- Schedules pipelines
- Enables us to run our code locally or on external systems
- Enables Observability with logs and metadata
2.1. Schedulers to run data pipelines at specified frequency
Batch data pipelines will need to be run at specific intervals. The frequency required may be as simple as hourly, daily, weekly, monthly, etc., or complex, e.g., 2nd Tuesday of every month.
Airflow uses a process called Scheduler that checks our DAGs(data pipeline) every minute to see if it needs to be started.
In addition to defining a schedule in cron format, Airflow also enables you to create custom timetables that you can reuse across your data pipelines.
In our code, we define our pipeline to run every day(ref link ).
with DAG(
"user_analytics_dag",
description="A DAG to Pull user data and movie review data \
to analyze their behaviour",
schedule_interval=timedelta(days=1),
start_date=datetime(2023, 1, 1),
catchup=False,
) as dag:
2.2. Orchestrators to define the order of execution of your pipeline tasks
With complex data pipelines, we want parts of our pipelines to run in a specific order. For example, if your pipeline is pulling data from multiple independent sources, we would want them to run in parallel. Apache Airflow enables us to chain parts of our code to run in parallel or sequentially as needed.
2.2.1. Define the order of execution of pipeline tasks with a DAG
Data pipelines are DAGs, i.e., they consist of a series of tasks that need to be run in a specified order without any cyclic dependencies.
A Directed Acyclic Graph (DAG) is a directed graph with no directed cycles. It consists of vertices and edges, with each edge directed from one vertex to another, so following those directions will never form a closed loop. (ref: wiki)
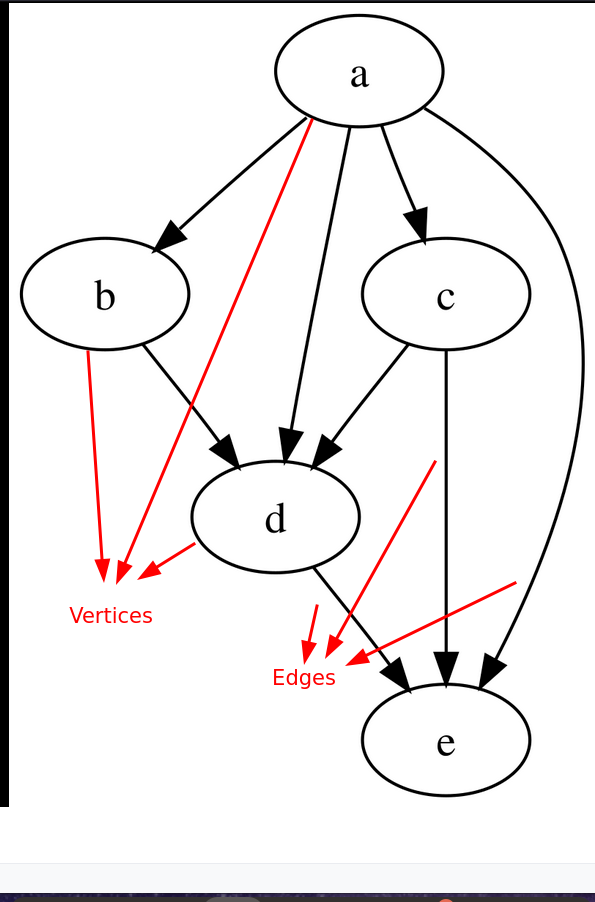
In data pipelines, we use the following terminology:
DAG: Represents an entire data pipeline.Task: Individual node in a DAG. The tasks usually correspond to some data task.Dependency: The edges between nodes represent the dependency between tasks.Upstream: All the tasks that run before the task under consideration.Downstream: All the tasks that run after the task under consideration.
In our example, if we consider the movie_classifier task, we can see its upstream and downstream tasks as shown below.
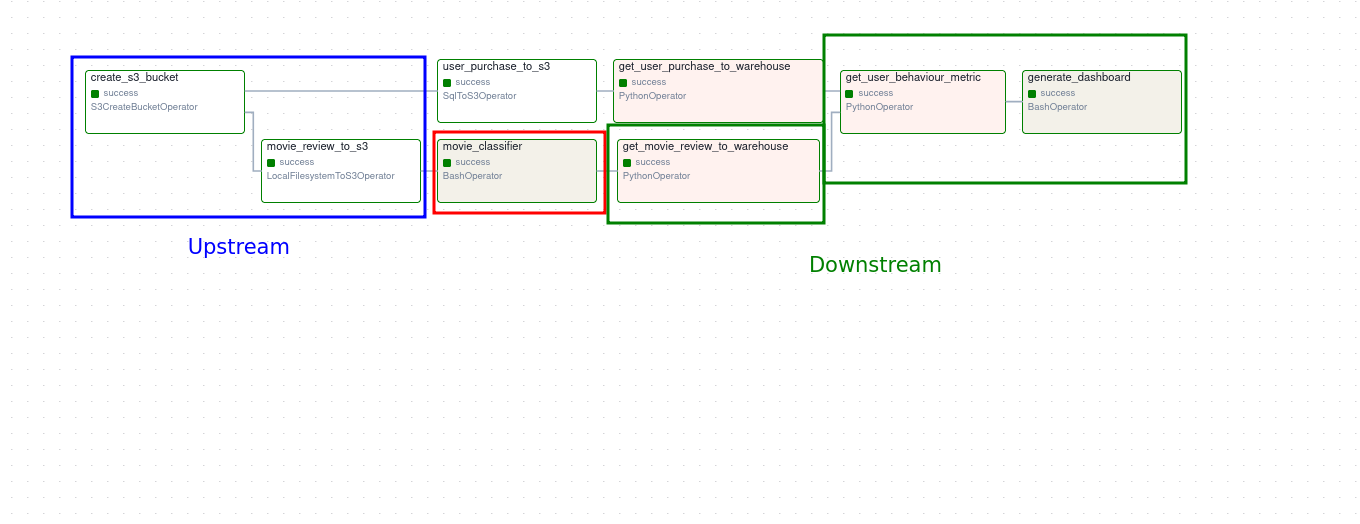
With DAG, we can define dependencies, i.e., we can define when a task runs depending on upstream tasks (ref: trigger rules )
We can also set individual task-level settings, such as the number of retries per task and branch logic, where you can define logic to choose one or more tasks out of multiple tasks. We can dynamically create tasks based on your logic.
In our code we define our DAG using the >> syntax (ref link
).
# Define the tasks
create_s3_bucket >> [user_purchase_to_s3, movie_review_to_s3]
user_purchase_to_s3 >> get_user_purchase_to_warehouse
movie_review_to_s3 >> movie_classifier >> get_movie_review_to_warehouse
(
[get_user_purchase_to_warehouse, get_movie_review_to_warehouse]
>> get_user_behaviour_metric
>> gen_dashboard
)
2.2.2. Define where to run your code
When we run our DAG, each task will be run individually. Airflow enables us to run our tasks in multiple ways:
- Run code in the same machine as your scheduler process with Local and sequential executor
- Run code in a task queue (i.e. a system that will run tasks in individual machines) with a celery executor.
- Run code as k8s pods with Kubernetes executor.
- Write custom logic to run your tasks.
See this link
for more details about running your tasks. In our project, we use the default SequentialExecutor, which is set up by default.
2.2.3. Use operators to connect to popular services
Most data pipelines involve talking to an external system, such as a cloud storage system (S3), data warehouse (Snowflake), or data processing system (Apache Spark).
While we can write code to work with these external systems, Apache Airflow provides a robust set of Operators for most services we can reuse.
In our code, we use multiple Airflow operators to reduce the amount of code we have to write (ref code ):
create_s3_bucket = S3CreateBucketOperator(
task_id="create_s3_bucket", bucket_name=user_analytics_bucket
)
movie_review_to_s3 = LocalFilesystemToS3Operator(
task_id="movie_review_to_s3",
filename="/opt/airflow/data/movie_review.csv",
dest_key="raw/movie_review.csv",
dest_bucket=user_analytics_bucket,
replace=True,
)
user_purchase_to_s3 = SqlToS3Operator(
task_id="user_purchase_to_s3",
sql_conn_id="postgres_default",
query="select * from retail.user_purchase",
s3_bucket=user_analytics_bucket,
s3_key="raw/user_purchase/user_purchase.csv",
replace=True,
)
The above code shows how we use Airflow operators to create S3 buckets and copy data from local files and a Postgres db into an S3 bucket. See here for a list of Airflow operators .
2.3. Observability to see how your pipelines are running
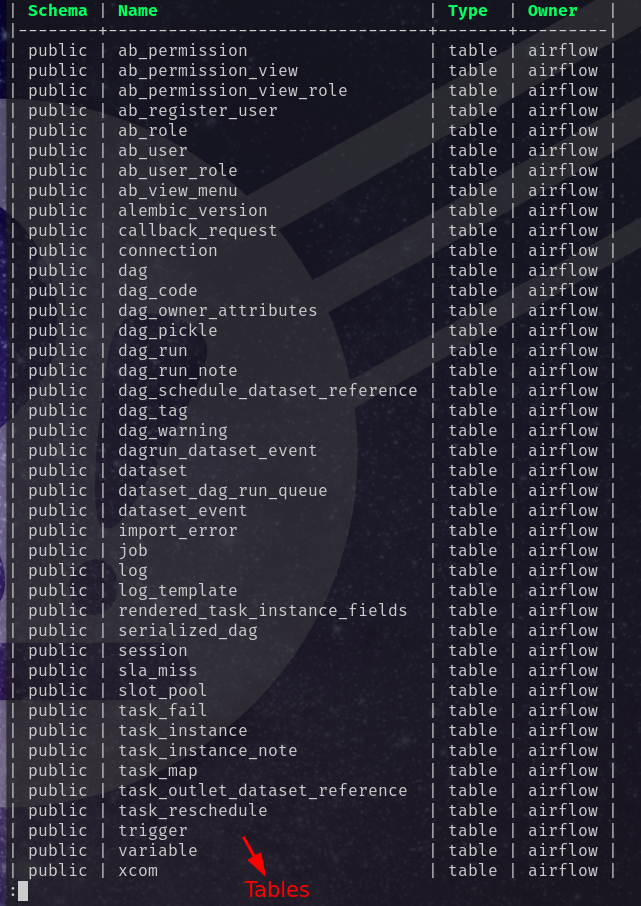
When a data pipeline runs, all information is stored in a metadata db and as logs. The historical information allows us to observe your data pipelines’ current state and historical state.
Here is a list of the tables used to store metadata about our pipelines:
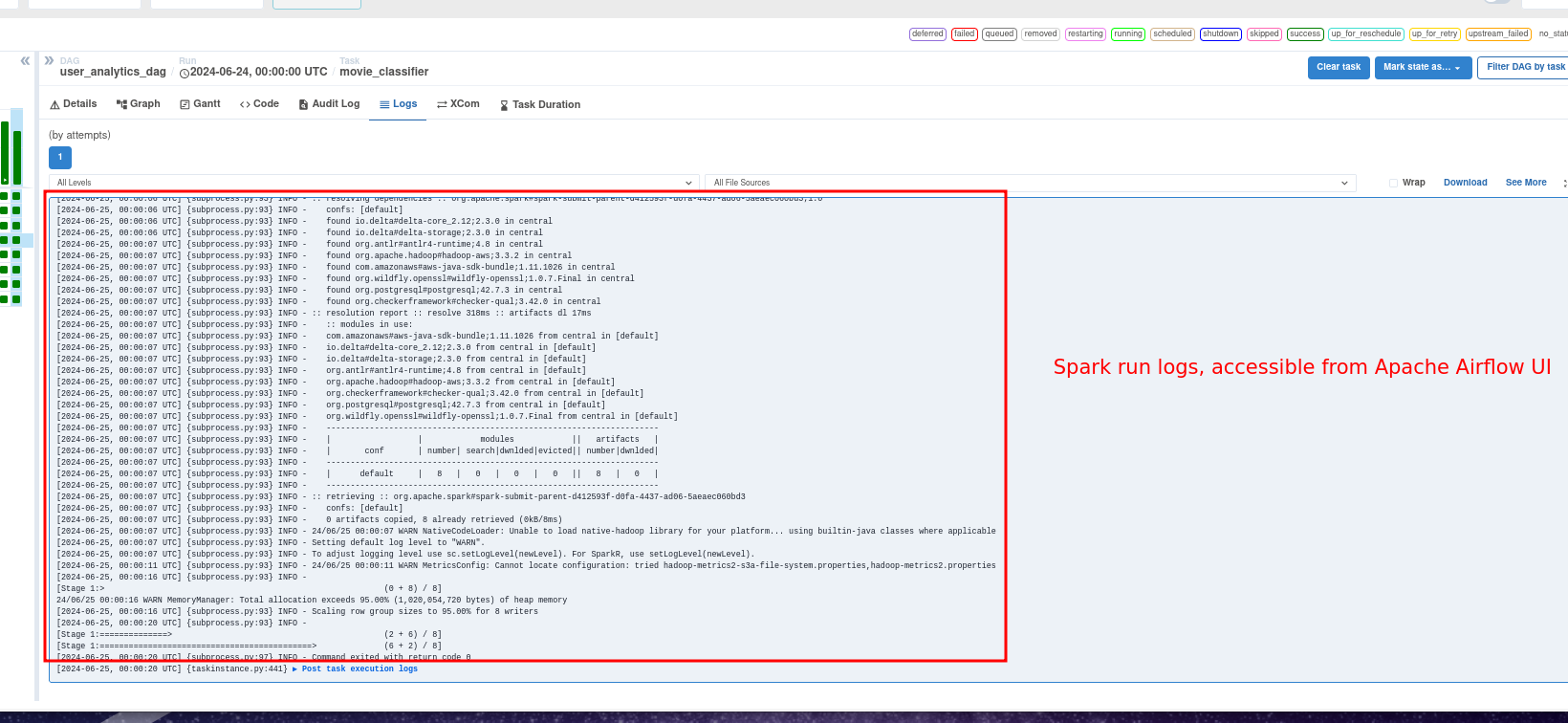
Apache Airflow enables us to store logs in multiple locations (ref docs
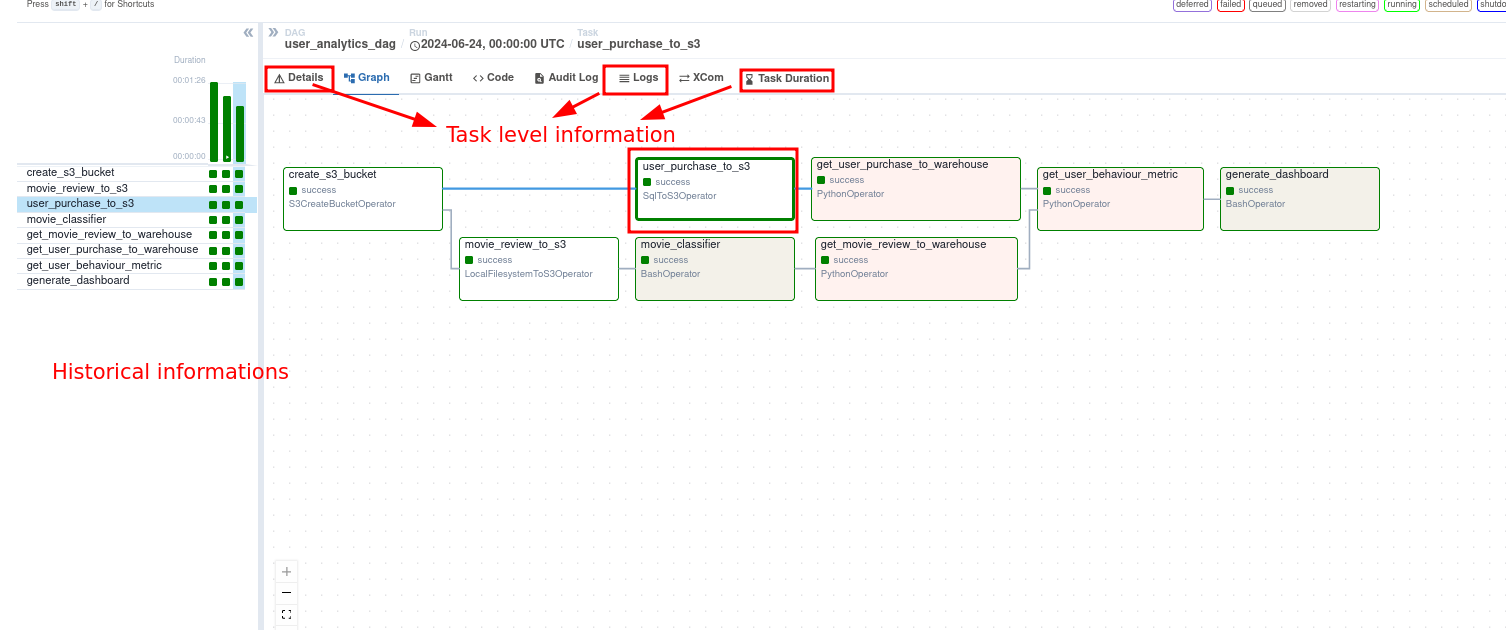
). In our project we store them locally in the file system, which can be accessed by clicking on a specific task -> Logs as shown below.
2.3.1. See progress & historical information on UI
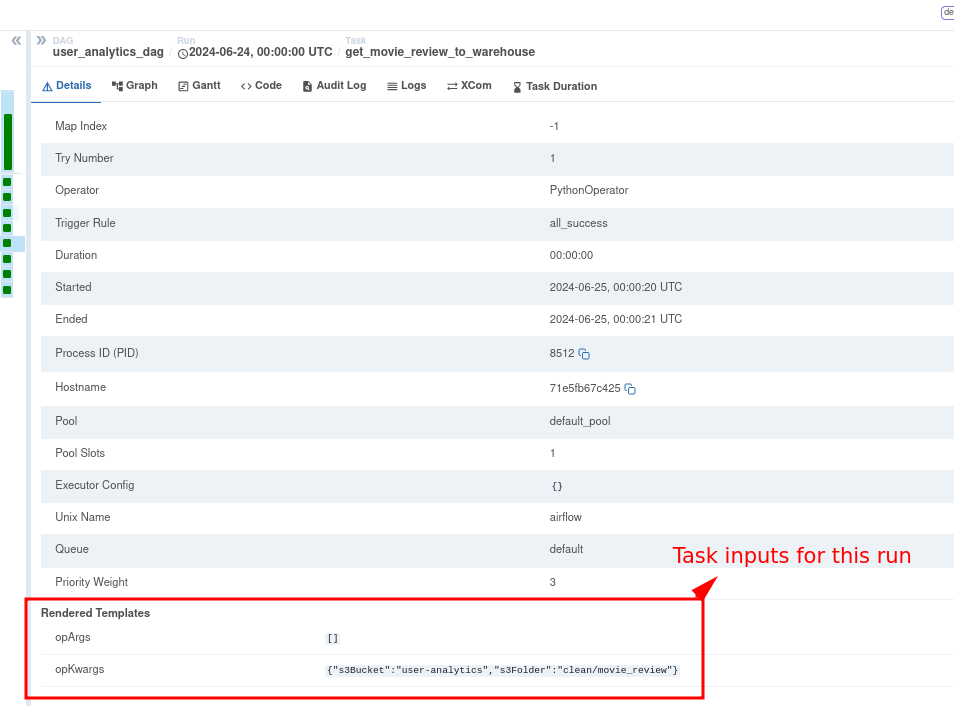
When we run data pipelines, we can use a nice web UI to see the progress, failures, and other details. Powered by the metadata db and the logs, we can also see individual task logs and the inputs to a specific task, among others.
The web UI provides good visibility into our pipelines’ current and historical state.
2.3.2. Analyze data pipeline performance with Web UI
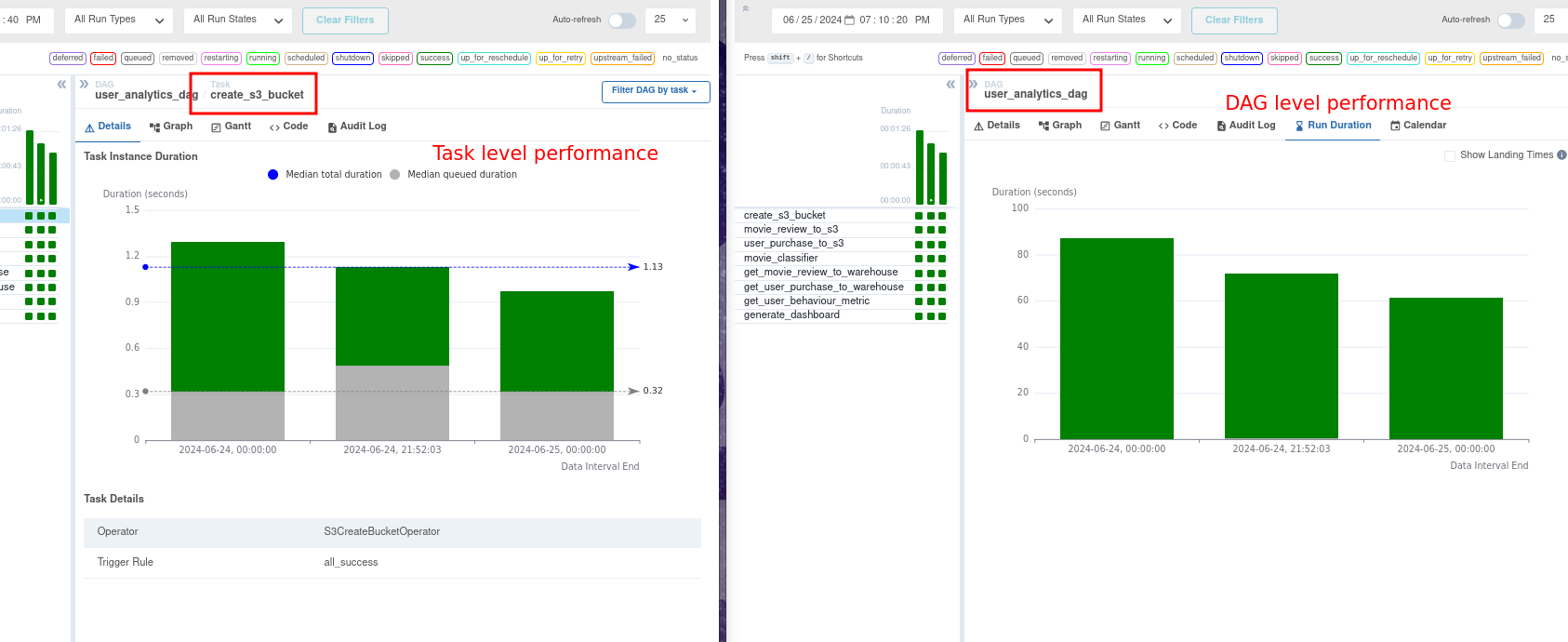
We can see how pipelines have performed over time, inspect task run time, and see how long a task had to wait to get started. The performance metrics provide us with the necessary insights to optimize our systems.
2.3.3. Re-run data pipelines via UI
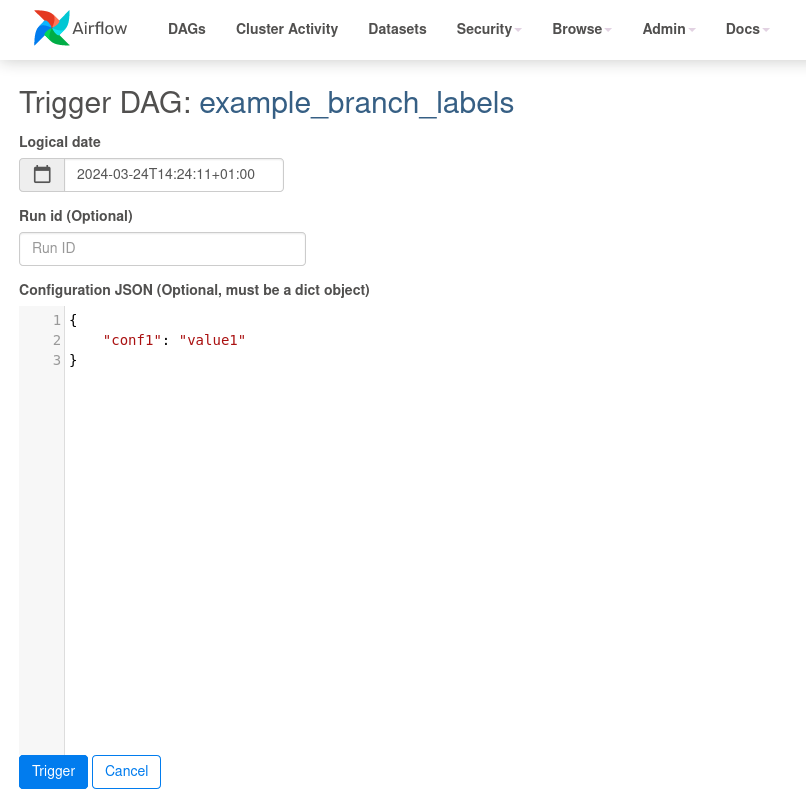
In addition to seeing how our pipelines are running, we can manually trigger DAGs with custom inputs as necessary. The ability to trigger/re-run DAGs helps us quickly resolve one-off issues. See this link for information on triggering dags with UI and CLI.
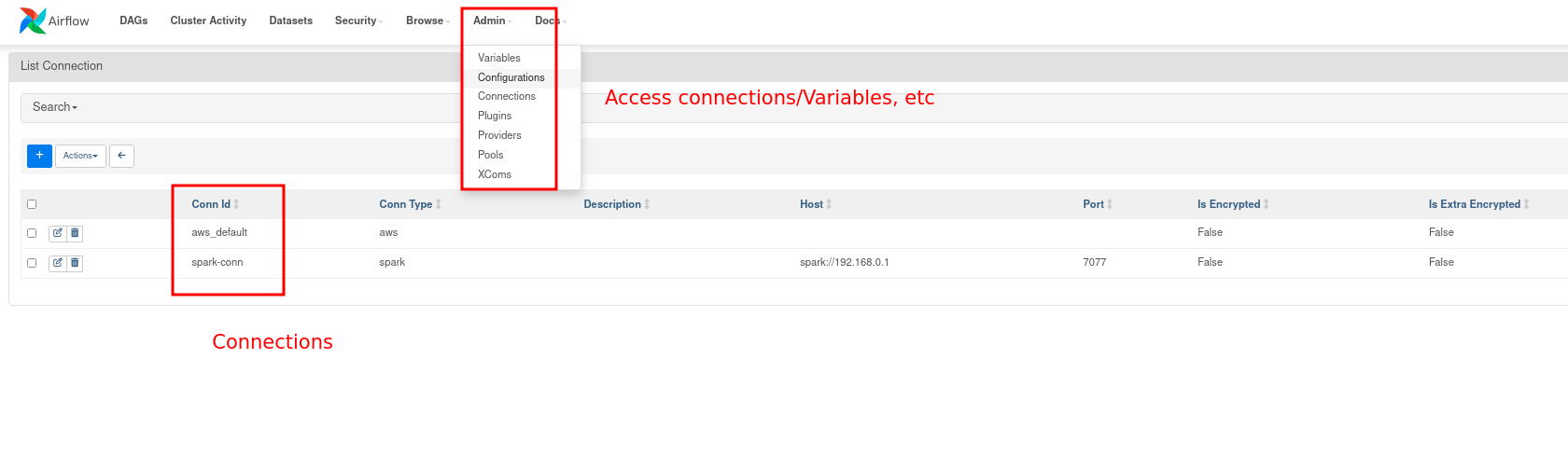
2.3.4. Reuse variables and connections across your pipelines
Apache Airflow also allows us to create and store variables and connection settings that can be reused across our data pipelines. In our code, we create variables using Airflow CLI here .
Once the connection/variables are set, we can see them in our UI:
2.3.5. Define who can view/edit your data pipelines with access control
When managing Airflow used by multiple people, it can be beneficial to have some people have limited access to the data pipeline. For example, you want to avoid a stakeholder being able to stop or delete a DAG accidentally.
See this link for details on access control.
3. Conclusion
To recap, we saw how Apache Airflow.
- Schedules pipelines
- Enables us to run our code locally or on external systems
- Enables Observability with logs and metadata
While Apache Airflow may be overkill for simple pipelines, as your data pipeline complexity and team grow, it can provide a cleaner way of doing things than implementing these features yourself.
Please let me know in the comments below if you have any questions or comments.
4. Further reading
- Data pipeline project with Apache Airflow and Apache Spark
- Python essentials for data engineers
- Data engineering best practices
If you found this article helpful, share it with a friend or colleague using one of the socials below!
A Directed Acyclic Graph (DAG) is a directed graph with no directed cycles. It consists of vertices and edges, with each edge directed from one vertex to another, so following those directions will never form a closed loop. (ref: wiki)